




Amazon Athenaについてまとめています。
目次
Amazon Athenaは、S3上のデータをSQL操作できるサービス

Amazon Athena はAmazon S3 内のデータをデータベースのように扱い、標準 SQL を使ってデータの抽出や分析を行うサービスです。Athena はサーバーレスでじっこうされ、インフラストラクチャの管理は不要。実行したクエリに対してのみ料金が発生します。
【関連記事】
▶AWS S3ってどんなサービス?初心者向けに機能紹介
Athena を使うには、Amazon S3 にあるデータを指定し、スキーマを定義します。その後、 SQL を使用してクエリの実行をおこないます。Athena を使うことで、分析用データを切り出すための複雑な ETL ジョブが不要になります。大型データセットに対して、誰でもSQLを使って簡単に分析をおこなうことができるようになるんですね。
Athena は、AWS Glueデータカタログと統合されていて、色んなサービスのメタデータの統合リポジトリを作成できます。データソースのクロール、スキーマの解析、テーブル定義、パーティション定義、スキーマのバージョニング保持が可能。
【関連記事】
▶データ分析をしたい!最新ETL機能AWS Glueを徹底解説!
AWS Athenaの利点
Athena はサーバーレスで、ETL不要。サーバーやデータウェアハウスの設定や管理は不要で、すぐにデータのクエリを実行できます。Amazon S3 上のデータを指定して、スキーマを定義し、組み込みのクエリエディタで開始できます。Amazon Athena でS3のユーザーデータを利用できるため、データ抽出、変換、ロード (ETL)などの複雑な処理は不要です。
スキャンしたデータに対してのみの支払いです。Amazon Athena は、実行クエリにのみ料金が発生。クエリごとにスキャンデータ量に基づく料金請求がされます。具体的な目安としては、1 テラバイトごとに 5 ドル 。データの圧縮、分割、列形式への変換により、クエリのコストを 30%~90% 削減、パフォーマンス向上させること可能です。S3 以外のストレージ料金は発生しません。
Amazon Athenaでは、ANSI SQL に準拠した Prestoを採用。Prestoは、低レイテンシー&アドホックなデータ分析用に最適化されたオープンソースの分散SQLクエリエンジンです。CSV、JSON、ORC、Parquet等の標準データフォーマットに対応しています。AthenaのJDBCドライバー経由で、様々なBIツールからAthenaを接続することもできます。単純なクエリ以外にも、大きな結合、ウィンドウ関数、配列などの複雑な分析も対応しています。
大きなデータセットに対してもパフォーマンスが高いです。内部的に、Amazon Athenaは自動的に並列処理がされているため、応答が高速なんですね。一般のRDBMSならフリーズしてしまうような重いクエリも多くの場合、数秒で結果が返ってきます。負荷が低くなるようにSQLを手動で最適化する必要はありませんし、パフォーマンスチューニングやクラスタの管理は不要です。
AWS Athenaでは、リレーショナル、非リレーショナル、オブジェクト、カスタムデータソースに対してSQLクエリを実行できます。複数の異なるデータソース対象にSQLを使ってデータを結合して解析を実行できるんですね。「横串検索」のようなクエリが可能です。
Amazon Athenaの使い方
Amazon Athenaを使うには、Athena コンソール(AWSマネジメントコンソールから開けます)にログイン後、コンソールウイザードまたは、DDL ステートメント入力によりスキーマ定義をおこないます。
関連)Athena コンソール
【関連記事】
▶AWSを集中管理したい!AWS マネジメントコンソールを使いこなそう!
Amazon Athenaのクエリエディタからは、「データソースからテーブルを作成」または、「SQLを使用して作成」によりテーブル作成が可能です。
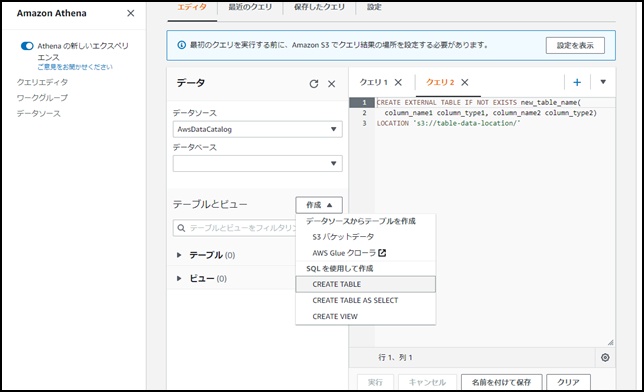
以下は、クエリエディタでテーブルを作成するDDLの例です。
CREATE EXTERNAL TABLE IF NOT EXISTS cloudfront_logs ( `Date` DATE, Time STRING, Location STRING, Bytes INT, RequestIP STRING, Method STRING, Host STRING, Uri STRING, Status INT, Referrer STRING, ClientInfo STRING ) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' LINES TERMINATED BY '\n' LOCATION 's3://athena-examples-my-region/cloudfront/plaintext/';
このDDLでは、テーブル「cloudfront_logs」が存在しないときのみテーブルを作成します。対象ファイルのロケーションは、s3://athena-examples-my-region/cloudfront/plaintext/で、カラムはタブ区切り、レコードは改行区切りのフォーマットを指定しています。
以下は、cloudfront_logsからデータを抽出するSQLの例です。date(日付)が、2014年7月5日~2014年8月5日のデータを、OSごとにグルーピングして、件数をカウントするSQLです。
SELECT os, COUNT(*) count FROM cloudfront_logs WHERE date BETWEEN date '2014-07-05' AND date '2014-08-05' GROUP BY os;
AWS Athenaの料金
Amazon Athena では、実行したクエリに対してのみ料金が発生します。各クエリでスキャンされるデータ量に基づいて課金されるんですね。データの圧縮、分割、列形式への変換を行うと、大幅なコスト削減とパフォーマンス向上を実現できます。例えば、GZIPを使ってファイルを圧縮した結果、サイズが1/3になったとすると、料金計算に使われるファイルサイズも1/3となります。スキャンするファイルサイズを減らすことが、料金の節約につながるんですね。
Amazon Athenaの料金はリージョンごとに異なります。北カリフォルニアリージョンの場合、スキャンされたデータ 1 TB あたり 6.75USD。なお、アジアパシフィック(東京)リージョンだと、1TBあたり5.00USDとなっていました。
【関連記事】
▶AWSの料金は従量課金体系 AWS料金計算ツールの見積もり方法紹介
AWS Athenaのまとめ


- AWS Athenaは、Amazon S3ストレージ上のファイルを直接SQL操作できるサービス
- サーバレスで、料金はS3上のスキャンしたデータサイズを元に計算される
- リレーショナル、非リレーショナル、オブジェクト、カスタムデータソースに対してSQLクエリを実行できる


