




AWSがいくら素晴らしいといっても、やはり人間が作ったもの。つまり、AWSも一般的なコンピュータシステムと同じように障害は発生しているのです。しかも利用者が多いAWSのこと、一度発生すればその影響は計り知れないものがあります。
本記事では、AWSでは障害は起こるものとして、その障害情報をどうやって収集するか、また障害の影響を最小限にするにはどうすればよいのか、過去の障害の具体事例を解説します。
目次
AWS障害情報の集め方
AWSの障害情報をいかに効率的に集めるかを考えてみましょう。
まずは一番シンプルにダッシュボード
AWSマネジメントコンソールの上の黒い帯の、中央から少し右に寄ったあたりにベルのマークがあります。それをクリックすると「アラート」が表示されます。

表示されたら、一番下の「すべてのアラートを表示」をクリックしてください。すると、アナウンスのすべてが表示されます。
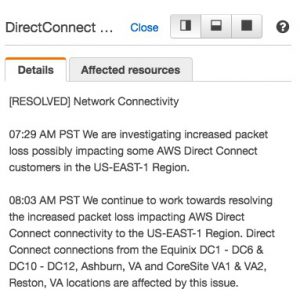
ただし、表示される情報すべてが英語なのに加えて、時刻がPST、つまり米国太平洋標準時という、アメリカの標準時で表示されているので、17時間の時差を逐一意識する必要があります。
この記事は、US-East-1(米国東部-バージニア北部)にて発生した、DirectConnectのパケットロスについて報じています。英語なので正直言ってわかりにくいですね。
RSSでAWSの障害情報を受け取る
RSSで障害情報を受け取ることができます。こちらをご覧ください。
また英語・・・
twitterでAWSをフォロー(非公式)
非公式ながらtwitterで障害情報をフォローできます。
<東京リージョンのみ>
<全世界>
ちなみに本物のAWSのtwitterは、宣伝がメインです。
<本家AWS>
IFTTTを使ってTwitterに連携する
IFTTT(イフト)というサービスをご存知でしょうか?
このサービスは、twitterをはじめとしてFacebook、インスタグラム、Slackなどなどの各種SNSやサービスを一手に連携してくれるというものです。つまり、twitterの障害情報とIFTTTを連携し、さらにFacebookなどなどのSNS系アプリと連携すれば、逐一アプリを切り替える必要がなくなります!
先ほどご紹介した障害情報のtwitterをtwitterアプリでフォローするより、IFTTTで複数のSNSと同時に連携したほうが便利そうですね!もちろん、スマホ用のアプリも無償で配布されています。

画面に入りきらないのである程度で大きさを区切りましたが、本当はもっと多数あります。興味のある方はぜひこちらをご覧ください。
AWSの障害を予防するためにできる対策
AWSに限らず、どのクラウドプロバイダーでも障害は起きています。つまりクラウドを使うとなった途端に、障害は起きるものと割り切る必要があります。とはいえ、クラウド側の障害と共倒れにならないように、影響は最小限に食い止めたいものです。
では、どうすれば影響を最小限に止められるのかを考えていきましょう。
リスク分散
RDSであればMulti-AZを使って複数のアベイラビリティゾーンにリソースを分散させるとか、S3やEBSであれば別のリージョンにバックアップを持って行くといったリスク分散が必要です。とはいえこの辺は難しいのです。例えば東京リージョンにある個人データを海外のリージョンに持って行くことが許されるのかどうか、それは各企業が判断すべきであり、何が正解かは企業ごとに千差万別だからです。
あと、監視の仕組みを構築することも忘れてはなりません。CloudWatchを使う、オープンソースのZAbbixを使って監視する、そういった状況を把握できる仕組みが大事です。ただしこれも微妙で、同じリージョンの同じアベイラビリティゾーンに監視する仕組みを作ってしまうと、サービスとともに監視の仕組みも共倒れになりかねません。
しかし、死活監視程度なら大したリソースを食うわけでもないので、それこそ海外のリージョンから監視をさせても問題ないでしょう。
今までに起きた障害一覧
AWSで今までどのような障害が起きたのか解説します。もちろんAWSも報告書として公開しているのですが、文章が長いのと専門用語が多く理解しづらいので、ここに概要としてまとめました。日付と時刻は、いずれも日本時間で表記しています。
落雷による停電
2011年8月8日2時41分、EU-West(EU-West1がアイルランド、EU-West2がロンドンなのですが、いずれかまたはすべてなのかは報告書に記載なし)において、電力会社の変圧器(電圧を上げる、または下げる機械)の故障により電力の供給が止まりました。これによりEC2、EBS、RDSが影響を受けました。
直接の原因は、電力会社の変圧器への落雷が原因でした。この電力会社では、通常電力の供給が止まるとPLCという機器がバックアップ用の発電機を起動して電力供給を保とうとするのですが、PLC自体も故障していてそれができませんでした。
さらに無停電電源装置(UPS)という、いわゆるバッテリーが動作して電力が止まらないようにするのですが、そこは所詮はバッテリー。停電時間が長くUPSの電力の蓄えも尽きてしまいました。
全世界のAWSのデータセンターはそれぞれリージョンと呼びます。1つのリージョンの中は複数のアベイラビリティーゾーンという区画に分割されています。この事故で、障害のあったアベイラビリティーゾーンのほとんどすべてのEC2インスタンスと、58%のEBSボリュームへの電源が失われました。アベイラビリティーゾーン間、そしてアベイラビリティーゾンからインターネットへのネットワーク接続すらも失われました。完全に復旧したのは8月8日5時49分でした。
AWSはさらなる電力設備の冗長化を検討し、同時に止まった間に課金された料金はユーザーに返金しています。
しかしこの障害はもう1つ、電力会社とは関係がない大きな問題が発生していました。EBSを管理するソフトウェアの不具合です。AWS内では、どのEBSからも参照されていないストレージブロックをリストアップするアプリケーションが動作しています。そのアプリケーションが削除可能対象ブロックをリストにするので、それを人が確認し、さらに確認した人とは別の人が第三者チェックを行い、問題なければ人が削除を実行します。
リストアップするアプリケーションに不具合があり、削除してはいけないブロックまでリストアップされてしまいました。そのリストを人が目視で確認したのですが、不具合を見抜けず使用中のブロックまで削除してしまいました。このトラブルが、電力トラブルの起こる直前に発生していました。その復旧中に電力トラブルが発生したので、そちらに注力せざるをえませんでした。EBSのトラブルが復旧したのは8月9日8時19分でした。
結局、どうすればよいのでしょうか?
報告書を読んでいて気になるのは「EBSのトラブル復旧と同時にダッシュボードでアナウンスしました」と書いてあることです。つまり復旧中はダッシュボードにトラブルの情報はなく、ユーザーはおかしいと気づいていながら、なす術はなかったということです。
EC2やEBS、RDSと同時に、CloudWatchや他のサービスまで止まったかどうかまでは報告にはありません。可能な限り、他のサービスやインスタンスを使って死活監視を行うことが重要です。サービスによってはMulti-AZが使えますので、これを導入するのも手ですね。
オペレータのミス
こちらの障害は、なんとオペレータのコマンド入力ミスです。
2017年3月1日未明に、米国東部(バージニア北部、US-EAST-1)リージョンにおいて、オペレータのコマンド入力ミスにより予想以上の多数のS3が削除されてしまいました。
S3チームが、請求システムの少数のサーバーを削除しようとして、コマンド入力ミスにより予想以上の数のサーバーを削除してしまいました。
S3は大きく分けて2つのサブシステムに分かれます。それぞれがS3 APIに対するリクエストを分担しています。これらのサブシステムは、多数のリソースを削除すると再起動を要します。近年で急速に拡大したS3のサブシステムを再起動したことはなく、実際に再起動してみると予想以上の時間を要してしまいました。
その間、ユーザーからのリクエストに対応できず、さらにS3を使う他のAWSのサービス(EC2やEBSなど)まで影響を受けてダウンしてしまいました。
報告書によると、コマンド入力ミスを起こしたのは適切な権限を与えられたオペレータで、すでに確立された手順に則って行ったとのことです。ここまでくると、もう私たちでは防ぎようがないですね。
AWSは以下2点の対応策をとりました。
1つは、メンテナンスツールが短時間のうちに大量のサーバーを削除できないように、かつサブシステム自体のキャパシティを監視して一定以上下回らないようにしました。もう1つは、S3を「セル」と呼ばれる区画に分けて、局所的に作業を評価し、また他へ及ぼす影響を小さくなるようにしました。
共通していえること
複数の障害を調査したところ、大きく分けて「天災」「人災」「キャパシティー不足」が原因のようです。特に天災は多く、落雷や豪雨といった逃れようのないものです。あと多いのはオペレーションミスという人災です。
近年、AWSの規模は拡大する一方です。稼働率そのものは高いとしても、障害は起こるときには起こります。私たち利用者側もサービスを過信せず、Multi-AZを利用する、可能な限り複数のリージョンをまたいでバックアップを取るといった自衛策が必要なのを忘れてはなりません。
まとめ

本記事では、AWSの障害について解説しました。
ここ最近の世論を見ていると、クラウドのメリットや「クラウドファースト」といった用語の一人歩きをよく見かけます。しかしクラウドとはいえ人が作ったシステムであることには変わりありません。便利さの反面、当然あるべきの危険性を意識して使いこなしたいものですね。


