




ビックデータ時代において、これからのデータベースには、スケーラブルで低レイテンシーな仕組みが求められています。この記事では、これらの課題を解決する完全マネージド型のNoSQL データベースである Amazon DynamoDB を解説します。
データベースといえば関係データベースですが、従来のデータベースはいろいろと面倒な事が多いです。例えば、正規化が必要であったり、カラム追加がとても面倒だったり…
関係データベースは大量のデータが入るとパフォーマンスが低下するのも問題です。これではここ最近はやりのIoTや、その他最新技術で発生する大量データをさばくのも不安があります。
そんな不安を解消してくれるのが、今回解説する「Amazon DynamoDB」です!従来のデータベースの概念をくつがえすデータベースなので最初はとっつきにくいかもしれませんが、じっくりと考えれば決して難しいものではありません。ぜひ取り組んでみてください。
- Amazon DynamoDB はデータを JSONで保存するNoSQL データベース
- データ量が増えても性能が劣化しない設計
- ゲームや IoT などビッグデータを扱うシステムに向いている
- RDBのように複数のテーブルを結合できない
- 学習用途であれば十分な量の無料利用枠が用意されている
目次
Amazon DynamoDBとは
Amazon DynamoDB(ダイナモディービー)は、ざっくりいえばデータベースです。なぜ従来のデータベースがあるのにDynamoDBが登場したのでしょうか?
Amazon DynamoDBをはじめとしたいわゆるビッグデータをあつかうデータベースをKVS(キーバリューストア)型のデータベース、またはNoSQLデータベースといいます。
関係データベースの限界からの解放
IoTやビッグデータの活用が進むにつれて、関係データベースの限界が明らかになってきました。関係データベースでは縦と横の二次元の表の概念でデータを保存します。データ量が少ないうちはよいのですが、増えてくるといろいろと問題が出てきます。例えば、カラムの追加です。
すでに稼働している関係データベースにカラムを追加するのは一苦労です。ましてや、数億件のレコードが格納されている状態でカラムの追加をすると、追加し終わるまでに要する時間もさることながら、原因不明のエラーがかかって作業前の状態に戻すのにまた相当な時間…経験した事がある方いませんか?つまり二次元の表という概念が、大量データをさばくのに足かせになっているのです。もともと、関係データベースは無限のデータ量をサポートするといった発想がありません。
一方、Amazon DynamoDBやその他のKVS型・NoSQL型データベースは、データ量が膨大になったときのことを考えて作られています。
完全性(ACID特性)の呪縛からの解放
関係データベースの大きな特徴として、ACID特性があります。4つの大きな特徴を表す英単語の頭文字をとって、A,C,I,Dというのですが、特に大きな影響があるものだけをピックアップして解説します。
関係データベースは、いつ何時も完全であることを保証します。つまり更新したかしていないか、いずれの状態しか許しません。これだと、データ件数の増加と1アクションに要する処理時間は比例的に伸びます。
ところが、Amazon DynamoDBをはじめとするKVS型のデータベースは、「次に参照するまでに書き換わっていれば良い」という、ぬるーい動きをします。
考えようによってはデータは次に使うまでに最新になっていればよく、即時に完全性を目指す必要はユーザー側からみれば重要ではないですよね。この考えが、超大量データをあつかう場面での優位性を生み出しているのです。
Amazon DynamoDBの特徴
Amazon DynamoDBに特有の特徴と、KVS型やNoSQL型に一般的な特徴を合わせて解説します。
データは列方向に走査する
関係データベースは行単位にレコードを取得して処理します。それだと1カラムを検索するだけでも1行単位のレコードを取得する処理コストがかかります。ところがKVS型のデータベースは、列方向にデータを走査します。1行丸ごと取得することなく欲しい値を得られるのです。
性能はデータ量に依存しない
従来の関係データベースでは、データ量が増えるに従って性能が劣化します。ところがKVS型データベースはデータ量が増えても性能が劣化しません。Amazon DynamoDBでは、公称値の上ではデータ量に依存せず数ミリ秒以内でデータ取得が可能です。
JSON形式でデータを保存
Amazon DynamoDBは、データをJSON形式で保存します。もちろん、単純にJSON形式のテキストで、ではなくJSON形式のデータでの保存です。よって、取り出したらいきなりJSON形式なので、JavaScriptやその他の言語との相性がよさそうですね。この特性をドキュメント型データベースといいます。
Amazon DynamoDBの機能・できること
Amazon DynamoDBの機能面に注目し、何ができるのかを解説します。
高速・安定
Amazon DynamoDBはSSDをストレージに採用、さらに自動パーティション化により、データ数の規模によらず安定して高速な動作をします。
自動スケーリング
Amazon DynamoDBは、リクエスト量の増減によって自動的に容量を拡大・縮小します。これを自動スケーリングといいます。ユーザーはデフォルトで有効になっており、目標使用率を指定だけです。
その他多数の機能
Amazon DynamoDBは、ソフトウェアのアップデートやパッチ適用など一切不要です。また監視をAmazon CloudWatchに任せることもできます。それ以外にもAmazon Lambdaとの連携、蓄積したデータをAmazon Redshiftで分析、といった多数の機能があります。
未経験で、もっとクラウド開発や、データベースについて実績的に学習したい場合は、「ポテパンキャンプ」がおすすめです。最短5か月で未経験からプログラマー・エンジニアになれるプログラミングスクールです。
Amazon DynamoDBのできないこと
Amazon DynamoDBを語る上で、できないことを明確にすることはとても大事です。その上で移行すべきかそうでないかを判断する必要があります。
単独のソフトウェアとしての扱いが難しい
従来の関係データベースは、いわゆる独立したソフトウェアでした。例えばOracleやSQLServerは自分のPCにデータベースを持つことが可能でした。しかしAmazon DynamoDBはそれが困難です。AWSの公表しているローカルで実行するツールは一応あるにはありますが、jar形式で提供されており、若干扱いが難しいようです。
クライアントツールがあるにはあるけど・・・
OracleやMySQLのように、OSqlEditやMySQL Workbenchのように容易に操作できるクライアントツールがありません。ただしAWS公認以外にも一応はありますが、ここで紹介することはできません。興味のある方は「DynamoDB クライアントツール」といったキーワードでググってみてください。
複数テーブルの結合ができない
関係データベースでは普通に使えていたJOINが使えません。一般的にKVS型データベースはテーブル間の結合ができません。必要に応じてアプリ側で対応する必要があります。ここは、従来のデータベース設計者が一番とっつきにくいことではないでしょうか?
Amazon DynamoDBの用途
具体的に、どのような用途で使われているかを分野別に見ていきましょう。
ゲーム
モバイルやPCといったデバイスに関係することなく、ユーザーにストレスを与えずにサービスを提供するのは極めて大事なことです。ゲームになるとその重要度は特に高まります。ZyngaやWoogaといった(ちょっと日本では馴染みがない企業ですが)はAmazon DynamoDBをゲームに採用していることから、いかに高性能なのかがわかります。
IoT
デバイスが返す大量のデータをさばく必要があるIoTの分野でも、Amazon DynamoDBは活躍します。Canaryというホームセキュリティの企業は、コーヒーカップ程度の高さのビデオカメラとセンサーを各家庭に設置し、デバイスが送ってくる大量の映像とデータを解析しています。CanaryはデータをDynamoDBに保存し、そのデータをRedshiftで分析しています。
料金
料金計算の基本は、「キャパシティーユニット」です。書き込み、読み込みのいずれもキャパシティーユニット単位となります。書き込みをWCU、読み込みをRCUといいます。
例えば、書き込みでは1WCUあたり250万回まで可能です。1ヶ月を通して負荷が一定であると仮定して、1日あたり500万回の書き込みがあったとしましょう。割り算すると1秒あたり57.8回の書き込みになります。ということは、1WCUあたり1秒間に1回の書き込みを処理できるので、1秒あたり58WCUです。1WCUあたり0.47$なので月額27.26$となります。RCUも同じ要領で計算します。1RCUあたり0.09$です。
無料利用枠ではどこまで使えるの?
Amazon DynamoDBにも無料枠が用意されています。1か月あたり最大2億リクエスト(WCUが25ユニット、およびRCUは25ユニット)を処理するのに十分な量です。
始め方
AWSマネジメントコンソールから、データベース、DynamoDBと進んでください。
テーブルの作成
テーブル名をUSER、インデックスをidとします。

しばらくするとテーブルができます。これだけです。もっとさまざまな設定ができるのですが、スタートとしてはこれで十分でしょう。
次にデータを入れてみましょう。DynamoDBにおいて、テーブルは関係データベースと同じ意味です。関係データベースでいう行はDynamoDBでは項目といいます。
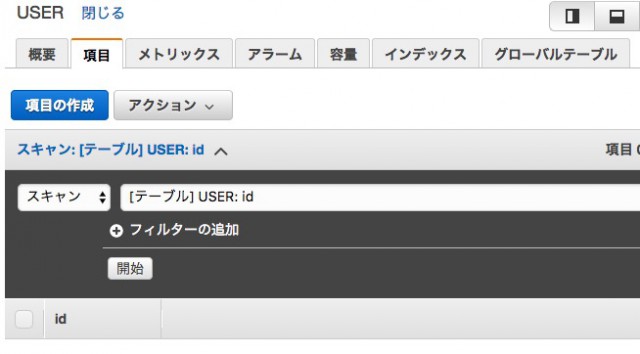
「項目の作成」ボタンをクリックしてください。
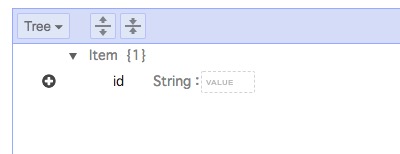
いわゆるデータ投入の画面ですが、ここで重要なことがあります。それは、どのカラムに何を入れる、といった従来のデータベースとはまったく異なるデータの入れ方をします。idはキー項目なので変更はできません。とりあえず入れてみます。
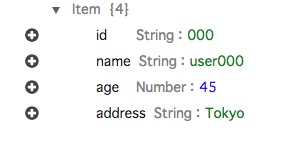
次に、以下のように入れてみましょう。
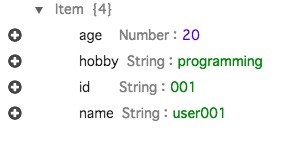
結果はこうなります。

お分かりでしょうか?
先ほど入力した行と必ずしもカラムは一致しない、つまりカラムはあらかじめ決めずに都度決めて良いということです。
基本的な使い方
今度は、先ほど入れたデータをAWS CLIでアクセスしてみましょう。
<コマンド>
aws dynamodb scan --table-name hello-dynamodb
<実行結果>
aws dynamodb scan --table-name USER
{
"Items": [
{
"hobby": {
"S": "programming"
},
"id": {
"S": "001"
},
"user_name": {
"S": "user001"
},
"age": {
"N": "20"
}
},
{
"address": {
"S": "Tokyo"
},
"id": {
"S": "000"
},
"user_name": {
"S": "user000"
},
"age": {
"N": "45"
}
}
],
"Count": 2,
"ScannedCount": 2,
"ConsumedCapacity": null
}
もうアクセスできました。JSON形式なのはお分かりいただけたでしょうか。
まとめ
本記事では、Amazon DynamoDBを解説しました。データ量が多くなると、従来の関係データベースで対応しきれなくなります。となると、このようなビッグデータに最適なDBの導入を考えざるをえません。これを期に、Amazon DynamoDBの導入を検討してみてはいかがでしょうか?


