




AWS Glueについてまとめています。
目次
AWS Glueは、ETL支援サービス 数分で分散システムからのデータ取り込みシステムが完成

AWS Glueは、データ分析に使うために、他のデータベースなどからデータを抽出、変換して、分析用データベース(データウェアハウス)にデータを格納するETL(Extract Transform Load)をおこないます。
関連)AWS Glue(分析用データ抽出、変換、ロード (ETL) )| AWS
ETLは、1970年代ごろから使われている概念としては古い言葉で、分散システムのデータを一箇所に集めてBI(ビジネス・インテリジェンス)で分析をおこなう前準備として、データを整備するためのものだったんですね。対象のシステムはデータベース形式や、文字コード、格納されたデータ構造などがバラバラで、それらを一箇所ののデータウェアハウスに格納するために、従来は対象システムごとにスクラッチで1から開発されてきました。
そのうち、都度開発していたら効率が悪いというので、各システムのETL用に共通して使い回せるETLツールが登場してきたんですね。AWS用のETLツールがAWS Glueというわけです。
【関連記事】
▶データ分析をしたい!最新ETL機能AWS Glueを徹底解説!
AWS Glueの使い方
AWS Gluesのコードベースいんたフェースは、具体的にはPythonまたはScala言語のライブラリ(モジュール)として提供されます。AWS Glueのモジュールを使ってコーディングすると、スクラッチで作るよりも遥かに簡単にETLが構成できるんですね。
以下は、GitHubに公開されている、AWS Glueのモジュールを使ってETLをおこなうコードです。コメント含めて54行のコードで、S3上に配置されているcsv形式のデータを読み込み、データベースに格納します。
# Copyright 2016-2020 Amazon.com, Inc. or its affiliates. All Rights Reserved. # SPDX-License-Identifier: MIT-0 import sys from awsglue.utils import getResolvedOptions from pyspark.context import SparkContext from awsglue.context import GlueContext from awsglue.dynamicframe import DynamicFrame from awsglue.job import Job from pyspark.sql.functions import udf from pyspark.sql.types import StringType glueContext = GlueContext(SparkContext.getOrCreate()) # Data Catalog: database and table name db_name = "payments" tbl_name = "medicare" : :
引用:aws-glue-samples/data_cleaning_and_lambda.py at master · aws-samples/aws-glue-samples
from awsglue… の行で、AWS Glueのモジュールを読み込んでいます。
従来よりもETLを作成するスピードが上がるとは言っても、結局コーディングをおこなうのでは、デバッグやテスト、リリース後のメンテナンスなどが必要になってきます。そうなると、AWS Glueによる恩恵も薄れてきますよね。
そこで、AWS Glue Studioが用意されています。
AWS Glue Studioは、GUIインタフェースからAWS Glueが使用可能になります。
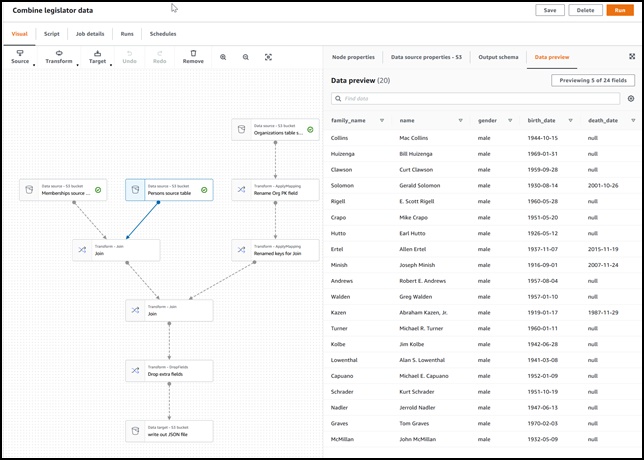
具体的には、以下が簡単に実現できる視覚的なインタフェースが用意されています。
- Amazon S3、Amazon Kinesis、または JDBC ソースからデータをプル。
- データを結合、サンプリング、または変換を構成します。
- 変換されたデータのターゲット位置を指定。
- ジョブの各ポイントで、スキーマまたはデータセットのサンプルを表示。
- 作成したジョブを実行、監視、管理する
関連)AWSGlue スタジオ – AWSGlue スタジオ
AWS Glue Studioは表形式データ以外に、アプリケーションログ、モバイルイベント、モノのインターネット (IoT) イベントストリーム、ソーシャルフィードなどの半構造化データ向けに設計されています。
AWS Glue カスタムコネクタ
AWS Glue カスタムコネクタは、AWS Glueで使える機能のひとつ。特定のSaaSアプリケーションとカスタムデータソースからS3にデータを簡単に転送できるようになります。例えば、Salesforce、SAP、Snowflace用のコネクタが用意されています。
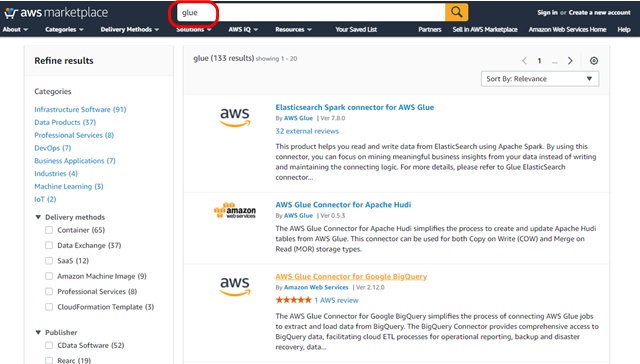
関連)AWS Marketplace: Search Results
AWS Marketplaceの検索窓に「glue」と入力することで、Glue カスタムコネクタの一覧が表示されます。
AWS Glueのメリット
AWS Glue は、分析、機械学習、アプリケーション用データの検出、準備、結合が簡単にできるサーバーレスデータ統合サービスです。AWS Glueを使うと、短いコードを記述するだけで、本来数ヶ月の開発期間を要するところを、数分で使用可能にします。
AWS Glue には、データ統合を容易にするために、GUIインターフェイスとコードベースのインターフェイスの両方が提供されています。
- ユーザーは AWS Glue Data Catalog を使用して、データを簡単に検出し、アクセスすることができます。
- データエンジニアと ETL (抽出、変換、読み込み) デベロッパーは、AWS Glue Studio で数回クリックすれば、ETL ワークフローを視覚的に作成、実行、モニターできます。
- データアナリストとデータサイエンティストは、AWS Glue DataBrew を使用して、コードを書くことなくデータを視覚的に強化、クリーンアップ、正規化できます。
- アプリケーションデベロッパーは、AWS Glue Elastic Views を使用して、使い慣れた構造化照会言語 (SQL) を使用して、さまざまなデータストア間でデータを結合および複製できます。
AWS Glueの利点は、大規模なデータ統合を自動化できる点と、サーバレス環境で稼働するためサーバ管理が不要な点です。利用料金は、ジョブが使用するリソースに対してのみの支払いとなります。
そのほか、AWS Glue を使用して、何千もの ETL ジョブを簡単に実行および管理できます。また、SQL を使って、複数のデータストア間にデータ結合およびレプリケートが可能です。
AWS Glueのまとめ


- AWS Gluesは、AWSのETL支援サービス
- AWS Glueには、GUIインタフェースとコードベースのインタフェース(ライブラリ)がある
- AWS カスタムコネクタを使うと、特定のアプリケーションやデータからの取り込みが簡単にできる


