




not existsを使うと、サブクエリに存在しないデータを抽出できます。
not existsの使い方、サンプル、注意点をご紹介致します。
目次
not existsの構文

SELECT [要素名] FROM [テーブル名]
WHERE not exists (
[副問い合わせのSELECT文]
)
not existsは、WHERE句で副問い合わせ(サブクエリ)と組み合わせて使用します。
副問い合わせの結果が存在しないとき、not existsは真となります。
クエリによっては、not existsをexistsを使って置き換えることも可能です。
not exists の書き方サンプルコード

not existsが実際、どういう場面で役に立つのか、サンプルコードを実行しながら見て行きましょう。
以下、データベースとして、MySQLのサンプルデータベースEmployeesを使っています。SQL実行結果の表示にはphpMyAdminを使用しています。
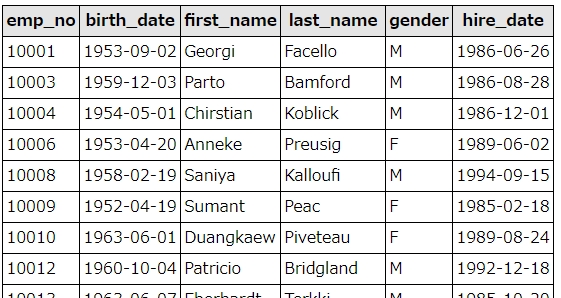
従業員テーブル(employees)から、役職(title)がStaff以外のデータを抽出するサンプルです。
SELECT * FROM employees WHERE not exists ( select * from titles where employees.emp_no = titles.emp_no and titles.title = 'Staff' )
結果はこうなります。役職が「Staff」の社員(社員番号10002,10005,10007,10011…)が除外されて抽出されています。
not existsは、基本的にjoinで置き換えられます。
SELECT * FROM employees join titles on employees.emp_no = titles.emp_no and titles.title != 'Staff'
joinで置き換えできないnot existsの使いかたを見て行きましょう。
not existsでどちらか片方にしかないデータを抽出
2テーブルのどちらか片方にしかないデータを抽出したい場合のサンプルです。
例えば、employeesテーブルにはデータが存在するが、titlesテーブルにはデータが存在しないというケースを想定してみます。

社員番号 500000のTaro Yamadaという社員のデータをemployeesテーブルにinsertしました。titlesテーブルには、何も挿入していません。
以下のクエリを実行してみます。
SELECT * FROM employees WHERE not EXISTS ( select * from titles where employees.emp_no = titles.emp_no )
実行結果はこうなります。
データが論理的に整合性を保っているかチェックするケース、例えば、リソーステーブルのデータ欠落チェックなどのために、not existsは役立ちそうですね。
同一テーブルの重複データを除外する
not existsのもうひとつの使い道は、重複データの除外です。
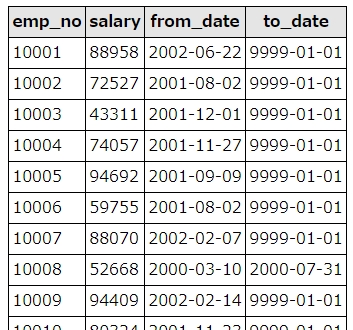
salaries(給与)テーブルから、to_date(有効日付)が最大のもの以外を除外します。
select * FROM salaries a
WHERE not exists (
select * from salaries b
where a.emp_no = b.emp_no
and a.to_date < b.to_date
)
エイリアス(別名)を使うことで、ひとつのテーブルを別々の2つのテーブルのように扱うことができます。
考え方は少々トリッキーで、「a.to_date < b.to_date」という条件により、to_dateに自身のデータ以下が存在するデータを抽出するサブクエリに対してnot existsを指定しています。
結果として、「to_dateが最大のもの以外除外」となります。
クエリの実行結果は以下の通り。
条件を「a.to_date > b.to_date」とすれば、最初の給与(初任給)のみを抽出するSQLになります。
SQL自体はシンプルですが、一から組み立てようとすると、なかなか思いつきません。
重複除外には、not_existsが使えるということを覚えておくと良いでしょう。
なお、少々複雑になりますが、inを使って記述することも可能です。
【関連記事】
SQLで重複を削除するサンプルコード 最新データを残してdeleteするには?
not existsはフルスキャンするので遅い

not existsのデメリットは、テーブルフルスキャン(全件走査)が実行されるため遅い点。
開発の場面では、できるだけ使用を避け、joinで置き換えるべきでしょう。
not existsを置き換えてパフォーマンスアップ
実際、joinに置き換えるとどの程度速くなるのでしょう?
MySQLにて、not exists版実行時にかかった時間は、以下の通り。
- 335917 total, Query took 0.0006 seconds.
join版に置き換えたときの実行時間は、こうなりました。
- 335917 total, Query took 0.0004 seconds.
実行時間は、約34%短縮。
条件が複雑になるほど、実行時間の差は開くと考えられます。
ただし、データベースによっては内部でSQLが最適化され、ほとんどパフォーマンスに影響しないケースもあります。
【関連記事】
NOT EXISTSとLEFT JOINの処理速度検証 Oralceでは実行結果はほぼ同じ
not exists select 1 と記述してもパフォーマンスは変わらない
古いデータベースでパフォーマンスをアップする裏技として、サブクエリのselect *をselect 1と記述するというものがありました。select *で全カラムを参照しなくても、存在するかどうか見ているだけだからselect 1を指定した方が早い、という理由です。
しかし、現在のデータベースは、内部でSQLの最適化がおこなわれるため、パフォーマンスは変わりません。
上記の重複を除外するSQLを、select 1に差し替えて、実行時間を比較してみましょう。
select * FROM salaries a
WHERE not exists (
select 1 from salaries b
where a.emp_no = b.emp_no
and a.to_date < b.to_date
)
select *の場合の実行時間
- Showing rows 0 – 24 (300180 total, Query took 0.0011 seconds.)
select 1の場合の実行時間
- Showing rows 0 – 24 (300180 total, Query took 0.0012 seconds.)
実行タイミングにより、select *またはselect 1がわずかに遅いケースがありましたが、誤差と言えるでしょう。
メンテナンス性を考えると、他人が「このコード、どういう意味だろう?」と迷うようなSQLは避けた方がよいでしょう。
短期集中でWebエンジニアになれるスクール
not existsの使い方まとめ


- not existsで、2テーブルの片方のみに存在するデータ抽出が可能
- not existsで、重複データ抽出クエリをシンプルに記述できる
- not existsは、実行速度が遅いので、可能な場合はjoinに置き換えて記述する
SQLを学んでWebエンジニアを目指そう
Webエンジニアは、Webサービスを作るエンジニアで非常に人気の高い職種です。
スタートアップやベンチャー企業が中心なので柔軟性のある雇用形態、魅力的な作業環境、面白いプロジェクト、高い報酬など非常に魅力的な求人が多いです。
Ruby on RailsやGo言語を用いたプロジェクトが多く、SQLも重要なスキルとなります。
このブログを運営するプログラミングスクールのポテパンキャンプでは、実践的なカリキュラムと現役エンジニアからのレビュー、そしてポートフォリオ添削や模擬面談などの面談転職サポートにより、最短距離でWebエンジニアを目指すことができます。
Webエンジニアへの転職を考えている方は、是非一度無料カウンセリングへお申込みください。


