




大規模データベースを運用していると、不要な重複データを削除したいケースがあります。
しかし、日常的におこなう作業ではないので、いざというときに「どうやるんだっけ…」と迷いがち。
そこで、コピペで実行できる、重複レコードを削除するためのSQLコードをご紹介致します。
以下、データベースとして、MySQLのサンプルデータベースEmployeesを使っています。SQL実行結果の表示にはphpMyAdminを使用しています。
目次
重複行を削除するためのサンプルSQLコード

重複している行のうち、最新レコードを抽出するサンプルコード
社員の給料の額が格納されているsalariesテーブルには、各社員(emp_no=社員番号)の年収(salary)が格納されています。from_dateとto_dateは、その年収が有効だった時期を表しています。
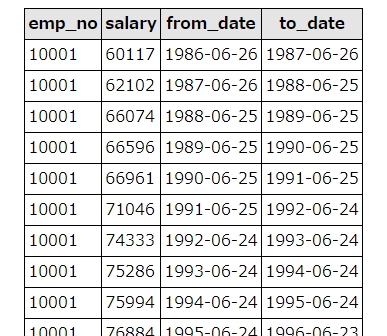
今回のサンプルでは、to_dateの値が最大のものを最新レコードとしました。同時に、having count(*) >1で、重複しているレコード数をカウントしています。
select emp_no, max(to_date) as to_date, count(*) from salaries b group by emp_no having count(*) > 1
実行結果は以下のとおりです。
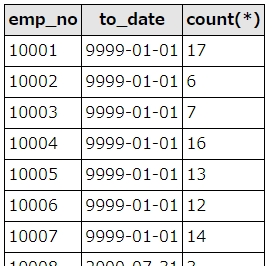
SQL実行結果
各社員の最新のto_dateと、重複件数が取得できました。
なお、to_dateが9999-01-01となっている行は最新の年収、それ以外の日付が入っている行は、すでに退職した社員の年収となっています。
重複行を抽出するサンプルコード
select * FROM salaries a WHERE (emp_no, to_date) not in ( select emp_no, max(to_date) as to_date from salaries b where a.emp_no = b.emp_no group by emp_no having count(*) > 1 )
副問い合わせ(サブクエリ)を使って、重複行を抽出します。テーブルの別名定義を使って、自己結合(セルフjoin)を行っています。
サブクエリで、「残したい行」を抽出して、not in でサブクエリの結果に含まれないデータを重複行として抽出しているんですね。
実行結果はこちら。
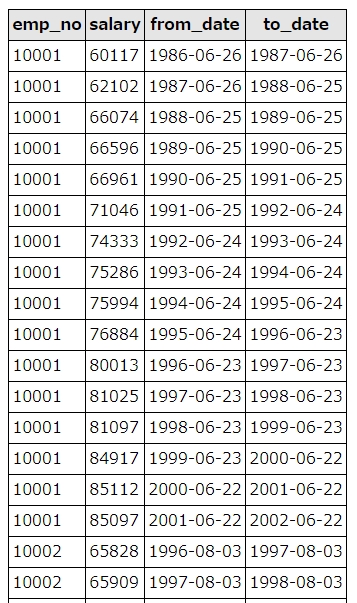
MySQLのDelete文では、テーブルの別名定義を使えない
先ほどのSQLの「select *」を「delete」に変えれば、重複削除SQLの出来上がり…と思ったのですが、MySQLの制約で、「Delete文で、テーブルの別名定義を使えない」というものがあります。
delete FROM salaries a WHERE (emp_no, to_date) not in ( select emp_no, max(to_date) as to_date from salaries b where a.emp_no = b.emp_no group by emp_no having count(*) > 1 )
※「select *」を「delete」に変更したSQL
実行すると、以下のエラーが出力されました。
#1054 - Unknown column 'b.emp_no' in 'where clause'
データベースによっては、上記SQLで動作します。
メインクエリに別名定義を使わずに、重複行を抽出するサンプルコード
少し改造を加えて、メインクエリでテーブルの別名定義を使わずに重複行を抽出するように変更しました。
select * from salaries where (emp_no, to_date) not in ( select tmp1.emp_no as emp_no, tmp1.to_date as to_date from ( select emp_no, max(to_date) as to_date from salaries group by emp_no ) as tmp1 )
改造前のSQLと同じ実行結果となりました。
メインクエリに別名定義を使わずに、重複行を削除するサンプルコード
「select *」を「delete」に変えて、重複行を削除してみましょう。
delete from salaries where (emp_no, to_date) not in ( select tmp1.emp_no as emp_no, tmp1.to_date as to_date from ( select emp_no, max(to_date) as to_date from salaries group by emp_no ) as tmp1 )
※先ほどと、ほぼ同じSQLですが、コピペして実行できるよう全コードを掲載しています。
実行すると、以下のメッセージが出力されました。
2543867 行削除しました。 (Query took 24.2313 seconds.)
254万行超の削除で、約24秒かかっています。
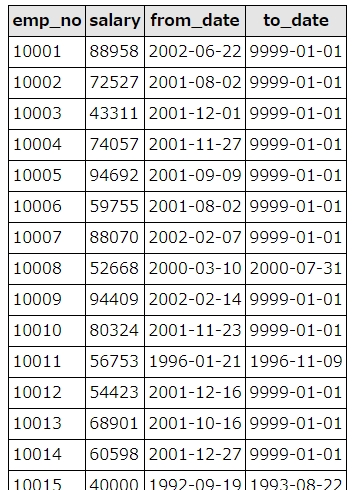
削除後のテーブルを確認してみましょう。
select * from salaries
最新のデータのみ残っていることが確認できました。
Delete+副問い合わせクエリは遅い
最終SQLの実行計画(explain)を見てみましょう。
explain select * from salaries where (emp_no, to_date) not in ( select tmp1.emp_no as emp_no, tmp1.to_date as to_date from ( select emp_no, max(to_date) as to_date from salaries group by emp_no ) as tmp1 )
メインクエリ(type=ALL)以外は、indexが使われているので、最適化されています。

実は、削除対象を検索するためにはindexは有効に働きますが、実際に削除する場合はindexがついているテーブルだと遅くなります。
複雑なクエリを伴うDeleteというのは、非効率とも言えるんですね。
対象テーブルの件数が多い場合、実行時間が数十分、数十時間、最悪SQLが応答不能に陥るケースも考えられます。
また、大量のdeleteをおこなったあとは、データベース内に「ごみ」が残り、データベースのパフォーマンスが悪化します。
delete処理後にOptimize tableを実行して、テーブルをデフラグすれば良いのですが、Optimize tableの実行自体に時間がかかるんですよね。
特に、本番データベースに対してこのようなSQLを発行するのは、危険な賭けと言えるかも知れません。
こちら、MySQLのデータをいろんな方法で削除した場合にかかる時間が記録されています。
参考)[MySQL]大量のレコードをDELETEする – Qiita
別テーブルに残したいデータを抽出後、テーブル名をリネームする方法

重複データ削除後のデータサイズが、ある程度小さい場合に使える方法です。
Deleteせずに、残したいデータだけ別テーブルとして作ったあと、テーブル名をリネームして入れ替えるという手順。
元データを消さずに作業を進められる上、大量Deleteによるデータベースのパフォーマンス悪化を避けられる点がメリットです。
参考)テーブル最適化(や大量のDELETE)をほぼ無停止で行う | Gumu-Lab.
SQLの重複データ削除方法まとめ


- サブクエリを使って、重複データを一気にdeleteすることが可能
- 大量データに対して実行すると、時間がかかることがある
- 別テーブルに残したいデータを抽出し、リネームする方法が有効なケースもあり


