




SQLのcount関数のサンプルコードを紹介致します。
なお、当記事はMySQLのサンプルデータベースEmployeesを、SQL実行結果の表示にはphpMyAdminを使って解説しています。
目次
countの基本的な使い方

countは、条件に合ったレコードの件数を数える関数です。
以下のように使います。
SELECT count(*) FROM employees where first_name = 'Anneke'
実行結果はこうなります。
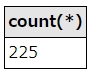
SQL実行結果
countのサンプルコード集

countで同一テーブルの異なる条件に合致するレコードの件数を数えるサンプルコード
SELECT count(first_name = 'Anneke' or NULL), count(first_name = 'Georgi' or NULL) FROM employees
count関数では、関数内に条件を記述することが可能です。
「first_name = ‘Anneke’ or NULL」は、条件に合致したレコードは真(1)になり、そうでなければNULLになります。count関数はNULLをカウントしないため、first_name=’Anneke’という条件に合致したレコードの件数を出力することになります。
この記述方法を使えば、一つのSQLで異なる条件に合致するレコード件数を取得できます。
上記SQLは、employees(社員テーブル)から、first_name(姓名の名)が「Anneke」のレコード件数と、first_nameが「Georgi」のレコード件数を取得します。
実行すると、こうなります。

countでグループごとのレコードの件数を数えるサンプルコード
countとgroup byと組み合わせると、グループごとのレコード件数を数えられます。
SELECT title, count(*) FROM titles WHERE to_date="9999-01-01" group by title
上記SQLは、titles(肩書テーブル)から、to_date(肩書の有効期限開始日)=9999-01-01(現在有効)のデータをtitle(肩書)ごとにグルーピングし、肩書と件数を取得するSQLです。
実行すると、こうなります。
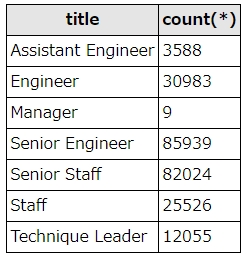
SQL実行結果
【関連記事】
▶SQLのgroup byサンプルコード集 count、like、join等の組み合わせ例
countでデータの種類数を数えるサンプルコード
countとdistinctと組み合わせて、重複しないデータをカウントすることで、データの種類数を取得することができます。
SELECT dept_name, count(distinct title) FROM `titles` left join dept_emp on titles.emp_no = dept_emp.emp_no left join departments on dept_emp.dept_no = departments.dept_no group by dept_name order by dept_name
上記SQLは、dept_name(部署名)と社員の肩書の数(データの種類)をカウントします。titles(肩書テーブル)、dept_emp(部署・社員紐付けテーブル)、departments(部署テーブル)をleft joinで結合し、dept_name(部署名)でグルーピングして、部署名でソートをおこなっています。
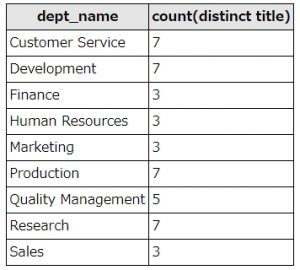
SQL実行結果
【関連記事】
▶SQL distinctのサンプルコード集 group byよりも700倍速い?
countで複数テーブルの件数を1つのSQLでカウントするサンプルコード
異なる複数のテーブルの件数を、countとサブクエリを使って1つのSQLでカウントできます。
select * from (select count(*) as employees_cnt from employees) a, (select count(*) as departments_cnt from departments) b, (select count(*) as salaries_cnt from salaries) c
employees(社員テーブル)の件数をemployees_cnt、departments(部署テーブル)の件数をdepartments_cnt、salaries(年収テーブル)の件数をsalaries_cntと別名定義し、取得しています。サブクエリを一つのテーブルとしてみなす際、同一テーブルとみなされないよう、テーブル名をa,b,cと別名定義しています。
実行するとこうなります。

SQL実行結果
countで重複数を条件にデータを取得するサンプルコード
havingで条件指定することで、count関数の結果をクエリの条件に組み込むことができます。
select hire_date,count(*) from employees group by hire_date having count(*) > 125
上記SQLは、employees(社員テーブル)から、同じhire_date(雇用日)が125件以上あるデータの、hire_date(雇用日)と件数を取得します。
実行するとこうなります。
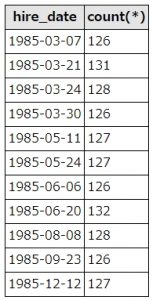
SQL実行結果
実行順序による制約から、countに対する条件はwhere句で指定できません。count、sum、avgなどの集約関数の条件はhavingで指定します。
count(1)と記述しても、実行速度は速くならない
昔のSQLコードには、count(*)とすべきところを、count(1)と記述していることがあります。
当時のデータベースは最適化機能が今ほど高性能ではなかったため、count(1)を記述することで多少の速度アップが図れたんですね。
最近のデータベースでは、count(*)とcount(1)の実行速度は同じです。
コードのメンテナンス時など、他者に無用の混乱を与える場合がありますので、count(1)という記述は避けましょう。
countを高速化するには、管理テーブルを利用
count(*)でテーブル件数を数えると、テーブルフルスキャンが実行されるため、件数が多くなるほど処理時間がかかります。
数千万件、数億件ともなると件数を取得するだけでも10分以上かかるケースがあるんですね。
DBMSによっては、管理テーブルを直接参照することでテーブルの件数を取得できます。
例えば、MySQLの場合は、以下のSQLを実行すると、指定したテーブルの全件数が一瞬で取得できます。
select table_rows from information_schema.tables where table_name = 'employees'
実行すると、こうなります。
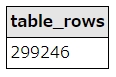
SQL実行結果
ただし、この数値は、実際の件数とズレることがあり、内部で統計的に算出しているようです。厳密な件数ではなく、ざっくりした値が取りたいときに使うと良いでしょう。
また、SQL Serverでも、システム・ストアドプロシジャのsp_spaceusedを使って、短い時間でテーブル件数が取得できるという情報がありました。
SQL Serverで大量レコードの件数を取得する | OISブログ
まとめ


- 同一テーブルの異なる条件のレコード数カウントには、count(条件 or NULL)を使う
- グループごとのレコード数カウントには、countとgroup byを組み合わせる
- データの種類数カウントには、countとdistinctを組み合わせる
- 複数テーブルの件数を1クエリで取得するには、countとサブクエリを組み合わせる
- countの結果をクエリの条件に組み込むにはhavingを使う
- count(1)とcount(*)の実行速度は変わらない
- 管理テーブルを直接参照で、大量件数カウントが一瞬でできるケース有り


