




SQLでdistnctを扱うサンプルコードをまとめました。
以下、データベースとして、MySQLのサンプルデータベースEmployeesを使っています。SQL実行結果の表示にはphpMyAdminを使用しています。
目次
SQL distinctのサンプルコード

distinctで重複をまとめる
distinctを使うと、重複行をまとめてデータを取得します。
構文は、「select distinct カラム名1,カラム名2… from テーブル名」。
下記は、dept_manager(部署ごとの管理職テーブル)から、部署ID(dept_no)を重複を除いて表示するSQLです。
SELECT distinct dept_no FROM `dept_manager`
実行結果はこうなります。

SQL実行結果
distinctを使わない場合はと比較してみましょう。
SELECT dept_no FROM `dept_manager`
実行結果はこうなります。

SQL 実行結果
重複したデータが、そのまま表示されます。
2つ以上のカラム指定で、distinct
distinctで複数のカラム指定も可能です。
SELECT distinct dept_name, title FROM `titles` left join dept_emp on titles.emp_no = dept_emp.emp_no left join departments on dept_emp.dept_no = departments.dept_no order by dept_name,title
上記SQLは、部署ごとの社員の肩書の種類を取得するものです。
titles(肩書テーブル)、dept_emp(社員番号と部署の紐付けテーブル)、departments(部署テーブル)をleft joinし、部署名(dept_name)とtitle(肩書)をorder byで並び替え指定したあと、distinctでまとめて表示しています。
distinctがdept_nameとtitleの両方に適用され、2つのカラムが重複しているレコードを除外します。
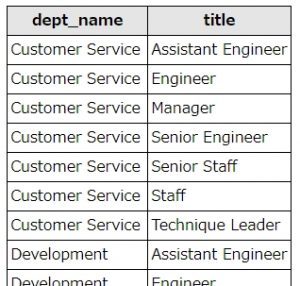
SQL実行結果
distinctは、重複する結果が出た時に便利ですが、「重複が出たらdistinct」と安易に考えると、バグを内在させることにもなりかねません。
取得結果に全く同じレコードが複数ある状態は正しいのか、テーブルの結合(join)の条件が間違っていないかなどを確認してから、distinctを使うようにすると良いでしょう。
distinctでデータの種類をカウントする
「count( distinct カラム名 )」で、データの種類をカウントすることができます。
SELECT dept_name, count(distinct title) FROM `titles` left join dept_emp on titles.emp_no = dept_emp.emp_no left join departments on dept_emp.dept_no = departments.dept_no group by dept_name order by dept_name
あ上記SQLは、部署名(dept_name)ごとの肩書(title)の数をカウントします。部署名をgroup by指定し、部署別にグルーピングをおこなっています。
実行結果はこうなります。
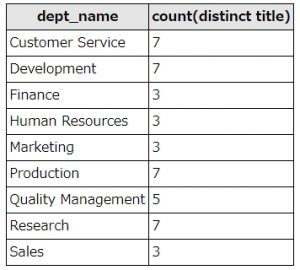
SQL実行結果
例えば、Customer Serviceには、7種類の肩書の社員がいますが、Financeには、3種類の肩書の社員しかいないことがわかります。
countの部分には、他の集約関数(sum、avg、min、maxなど)が使えます。ただし、distinctと組み合わせて意味があるケースは少ないと考えられます。
distinctをgroup byで置き換える
distinctは、group byの特殊なケースとして考えることができ、group byでSQLを置き換え可能です。
SELECT distinct first_name, gender FROM `employees`
上記は、employees(社員テーブル)から、first_name(社員のファーストネーム)、gender(性別)を重複を除いて抽出するSQLです。
以下のSQLに置き換えることが可能です。
SELECT first_name, gender FROM `employees` group by first_name, gender
なお、実行速度は、distinctが0.0003秒、group byが0.2112秒でした。
単純に見ると、group byは、distinctの約700倍時間がかかるということになります。しかし、複雑な条件や結合をおこなった場合には、実行速度が逆転する可能性もあります。
explainを実行すると、distinct使用SQLのextraには「Using temporary」(一時領域を使用)、group byのextraには「Using temporary; Using filesort」(一時領域を使用、ファイルソートを使用)と出ていました。
大量データを扱う場合など、レスポンスに大きな差が出そうな場合は、explain(実行計画)をチェックして、distinctかgroup byかを選ぶようにするのが無難でしょう。
distinct指定以外のカラムを取得するにはサブクエリを使用
distinctは重複除外に便利ですが、重複除外後の他カラムの取得ができません。
他のカラムを取得するには、distinctではなく、サブクエリを使います。
SELECT * FROM salaries a WHERE not exists ( select * from salaries b where a.emp_no = b.emp_no and a.to_date < b.to_date )
上記はsalaries(年収テーブル)から、to_dateが最新のもの以外を除外して、全カラムを取得するSQLです。
詳細は関連記事を参照してください。
【関連記事】
▶SQLで重複データを扱うサンプルコード集 カウント、集計、最新のみ抽出、重複禁止
distinctでは、暗黙のソートが実行されることがある
distinctを使用すると、内部処理でソートが実行されるケースがあるようです。
SQLの実行順序は、「order by」よりも「distinct」の方が後から実行されるため、一見するとorder byが効いていないように見えるケースがあります。
上記の参考リンクはpostgreSQLでの例ですが、例えばMySQLで以下を実行した場合は、特に問題なく結果を取得できました。
SELECT distinct * FROM `dept_manager` order by emp_no
上記SQLを実行すると、こうなります。
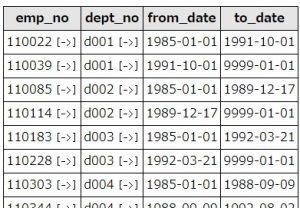
SQL実行結果
DBMSの違いや、バージョン等、SQLで扱うデータなどの条件により、ソート順が変わる可能性があることを覚えておくと良いでしょう。
まとめ


- 重複結果を安直にdistinctでまとめると、バグを内在させる可能性あり
- count()と組み合わせて、データの種類の数を取得できる
- distinct指定外のカラムを取得するには、サブクエリを使用する
- distinctの暗黙ソートに注意


