




SQLで重複データを扱うサンプルコードをまとめました。
以下、データベースとして、MySQLのサンプルデータベースEmployeesを使っています。SQL実行結果の表示にはphpMyAdminを使用しています。
重複データを集計するSQLサンプルコード

重複レコードをまとめるにはdistinctを使う
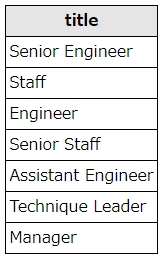
select distinct title from titles
社員約30万人分の役職情報が入っているtitlesテーブルから、title(役職名)を抽出し、distinctで重複をまとめます。
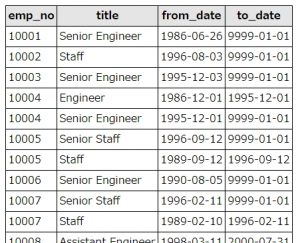
titlesテーブルは、以下のようなデータが入っています。emp_noは社員番号、titleは役職名、from_dateとto_dateはその役職が有効だった期間を表しています。
SQLの実行結果
SQLを実行するとこうなります。
SQLの実行結果
上記の役職名が抽出できました。
distinctは、selectで指定したカラムの重複を除外します。
SELECT DISTINCT first_name,
last_name,
gender
FROM `employees`
上記のSQLの場合、first_name, last_name, genderが全て一致しているレコードのみ重複除外されます。
重複のカウントには、group byとcountを組み合わせる
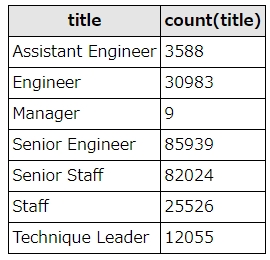
上記のSQLに手を加えて、同じ役職を持つ社員数をカウントしてみましょう。
ただし、社員によっては役職が変化した社員も居るため、条件として「在職している社員の最新の役職」(to_date=9999/01/01)を加えます。
SELECT title,
Count(title)
FROM titles
WHERE to_date = '9999/01/01'
GROUP BY title
実行結果はこうなりました。
SQLの実行結果
また、役職の数をカウントするには、countとdistinctを組み合わせます。
SELECT Count(distinct title) FROM titles WHERE to_date = '9999/01/01'
結果はこうなりました。

SQLの実行結果
7種類のtitle(役職)があることがわかりました。
重複を集計するにはgroup byと集計関数を組み合わせる
SELECT title,
Avg(salary),
Min(salary),
Max(salary)
FROM salaries
INNER JOIN titles
ON salaries.emp_no = titles.emp_no
WHERE salaries.to_date = '9999/01/01'
AND titles.to_date = '9999/01/01'
GROUP BY title
salaries(年収テーブル)と、titles(役職テーブル)をemp_no(社員番号)で内部結合しています。
salaries、titlesともにto_date=’9999/01/01’の最新データのみを対象にして、平均年収(avg)、最低年収(min)、最高年収(max)を集計してみました。
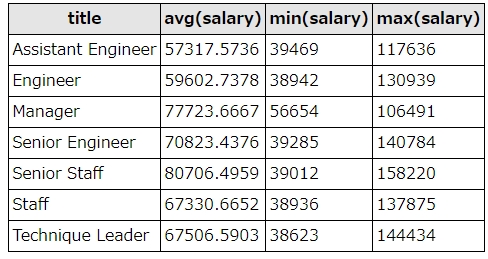
平均年収がもっとも高い役職はSenior Staffでした。役員も含まれているのでしょうか。
なお、集計関数はこの他にも、SUM(合計)、STD(母標準偏差)、VAR_SAMP(標本分散)などがあります。
重複データを除外するSQLサンプルコード

重複を除外して、最新のデータのみ残すにはサブクエリとnot existsを組み合わせる
SELECT * FROM salaries a
WHERE not exists (
select * from salaries b
where a.emp_no = b.emp_no
and a.to_date < b.to_date
)
not exists と サブクエリを使って、emp_no(社員番号)が重複し、to_date(有効期限 終了日)が最新のデータのみ抽出します。
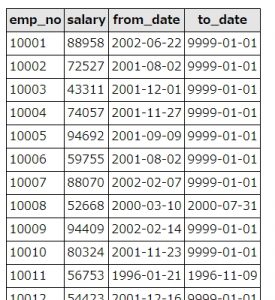
SQLの実行結果
エイリアスを使い、where句のa.to_date < b.to_dateという条件とnot existsを組み合わせて、最新データのみ残しています。
【関連記事】
▶SQL not exists サンプルコード 2テーブルの片方にしかないデータを抽出
重複データの優先順位を指定してデータを残す
上記SQLは「最新のデータのみ残す」ようにしましたが、where句を変えることで優先順位を指定して残すエータを決めることができます。
例えば、salaries(年収テーブル)のemp_no(社員番号)が重複しているデータから、salary(年収)が最も高いデータのみ抽出するSQLは以下のようになります。
where句の「and a.salary < b.salary」の部分のみ差し替えました。
SELECT * FROM salaries a
WHERE not exists (
select * from salaries b
where a.emp_no = b.emp_no
and a.salary < b.salary
)
SQLの実行結果はこうなりました。
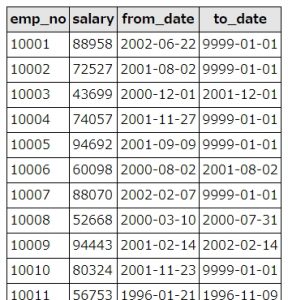
SQLの実行結果
必ずしも、最新の年収が最高とは限らないという結果になりました。
delete文と組み合わせて、実際に重複データを削除する方法は、こちらをご参考に。
【関連記事】
▶SQLで重複を削除するサンプルコード 最新データを残してdeleteするには?
日付の重複データを除外するには、date_formatとgroup byを組み合わせる
日付の入ったカラムを「年」で重複除外するサンプルコードです。
SELECT Date_format(birth_date, '%Y') AS birth_year,
Min(hire_date),
first_name,
last_name
FROM `employees`
GROUP BY birth_year
「同い年で、一番先輩は誰?」を求めるSQLです。
date_formatはMySQL独自の日付変換関数です。
具体的には、employees(社員テーブル)のbirth_date(誕生日)から、誕生年(birth_year)を抽出し、同じ誕生年の社員のうち、もっとも入社年月日(hire_date)が古い社員を抽出しています。
実行結果は以下のようになります。
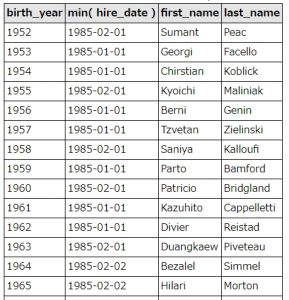
SQLの実行結果
条件を少し変えることで、「同い年で、一番後輩は誰?」「同期入社で一番年上は誰?」などを求めることが出来ます。
重複を禁止するSQL

ユニークキー制約で指定カラムの重複を禁止
テーブルのカラムのうち、プライマリキー以外のカラムの重複を禁止したい場合は、ユニークキー制約を設定します。
MySQLの場合は、以下のSQLでユニークキー制約が設定可能です。
ALTER TABLE テーブル名 ADD UNIQUE(カラム名)
ユニークキー制約は、複数の列に設定可能です。
ユニークキー制約を適用したカラムには、NULLを格納することができます。複数のカラムにNULLが格納されたときに重複とはみなされないので注意が必要。
NULLの重複制限は、DBMSによって異なります。MySQL、Oracleはユニークキー制約があってもNULL格納を許可にする設定が可能。SQL Serverは、NULL値も1列に一つしか使用できません。
関連)UNIQUE 制約と CHECK 制約 – SQL Server | Microsoft Docs
SQLの重複データのまとめ


- 重複データを単純にまとめるにはdistinctを使用
- 重複をカウントするには、group byとcountを組み合わせる
- 重複データを除外するには、サブクエリとnot existsを組み合わせる
- 重複データを禁止するには、ユニークキー制約を設定する


