




SQLのgroup byのサンプルコードを集めてみました。
グルーピングして集計したり、グループ内の最大値、最小値を求める際に便利です。
以下、データベースとして、MySQLのサンプルデータベースEmployeesを使っています。SQL実行結果の表示にはphpMyAdminを使用しています。
目次
group byで集計するサンプルコード

1つの項目を使って、group byで集計する例
部署番号(dept_no)と、社員番号(emp_no)を格納したテーブル、dept_empを使って集計してみましょう。
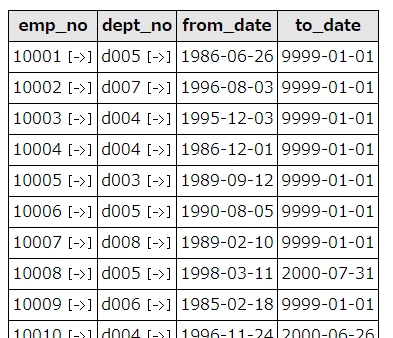
部署ごとの社員数を抽出してみましょう。
dept_noごとのレコードの数をgroup byで集計することで求められます。なお、在籍中の社員のみ対象とするために、to_date(在籍期間終了日)が”9999-01-01″の社員のみという条件を指定します。
SELECT dept_no, count(*) FROM dept_emp WHERE to_date = "9999-01-01" group by dept_no
結果はこうなります。並びは、dept_no順にソートされます。
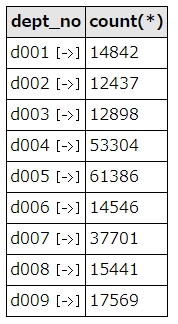
結果
group byの集計をjoin(結合)する例
せっかく集計したのですが、どの部署に何人いるのかわかりにくいので、テーブルdepartmentsと結合して、部署名(dept_name)を表示させましょう。
SELECT departments.dept_name, count(*) FROM dept_emp left join departments ON dept_emp.dept_no = departments.dept_no WHERE to_date = "9999-01-01" group by departments.dept_name
結果はこうなります。並びは、dept_nameでソートされます。
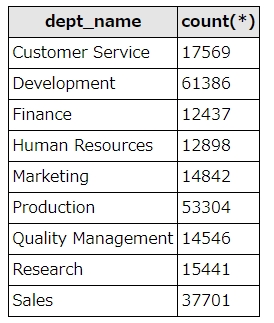
結果
likeを使ったワイルドカード指定のgroup by集計の例
テーブルtitles(肩書)を使って、ワイルドカード指定でgroup by集計をしてみましょう。
それぞれの肩書を持つ人数を抽出してみます。
titlesテーブルには、社員の過去の肩書も含まれていて、to_dateが”9999-01-01″のものが最新の肩書になります。
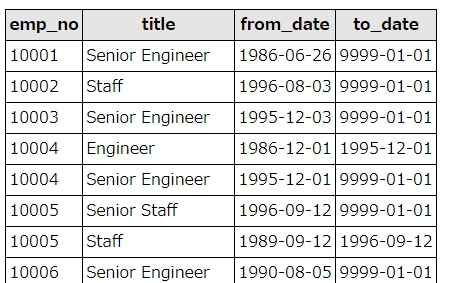
まず、単純にtitleで集計するとこうなります。
SELECT title, count(*) FROM titles WHERE to_date="9999-01-01" group by title
結果はこうなります。
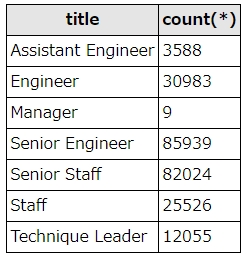
結果
「Assisttant Engineer」と「Engineer」と「Senior Engineer」、「Staff」と「Senior Staff」を、それぞれ一つにまとめて集計してみましょう。
それぞれlikeで”%Engineer%”、”%Staff%”とワイルドカード指定すればいけそうですね。
SELECT CASE WHEN title like '%Engineer%' THEN 'Engineer' WHEN title like '%Staff%' THEN 'Staff' ELSE title END as Katagaki , count(*) FROM titles WHERE to_date="9999-01-01" group by Katagaki
結果はこうなります。
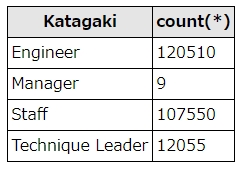
結果
CASEは、項目に条件分岐を含むプログラム処理的な動きをさせることができます。
group byでmax、min(最大最小)・平均・合計を求める例

salaries(給与)テーブルを使って、部署ごとに、もっとも高い給料をもとめてみましょう。
salariesテーブルには、各社員の過去の時点の給与も含まれているため、to_date=”9999-01-01″の、最新の給与のみ対象とします。
また、部署名を表示させるため、emp_dept(社員番号と部署番号テーブル)、departments(部署テーブル)を結合します。
SELECT departments.dept_name as bushomei, max(salary) as max_kyuuryo FROM salaries left join dept_emp ON dept_emp.emp_no = salaries.emp_no left join departments ON departments.dept_no = dept_emp.dept_no WHERE salaries.to_date="9999-01-01" group by bushomei
結果はこうなります。もっとも給与が高い社員がいるのは、Sales(営業部)でした。
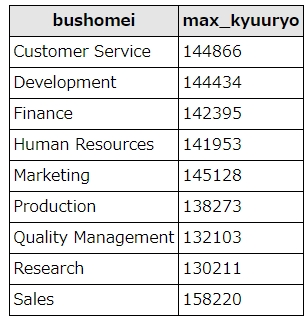
同様に、「 max(salary) as max_kyuuryo 」の部分を変更すれば、平均、最小、合計を求めることができます。
group byにminを組み合わせた例
minを使って、各部署の給与がもっとも安い人を求めました。
min(salary) as min_kyuuryo
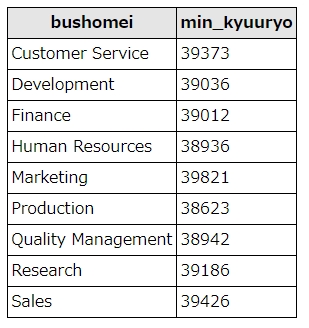
各部署とも、それほど大きな差はないようです。
group byにavgを組み合わせた例
avgを使って、各部署の平均給与を求めました。
avg(salary) as avg_kyuuryo
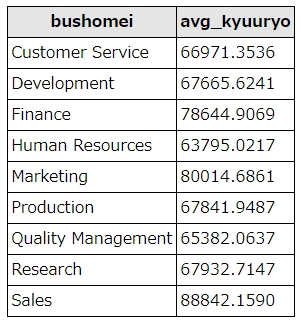
平均で見ても、営業部の給料は高め。
group byにsumを組み合わせた例
sumで各部署の給与合計を求めました。1年に支払われる給与合計がわかります。
sum(salary) as sum_kyuuryo
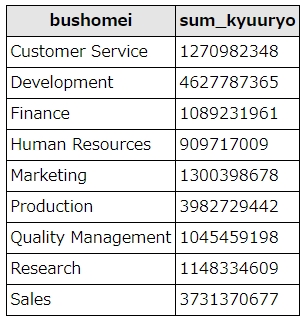
人数が多いため、Development(開発)部署の給与合計がもっとも高くなりました。
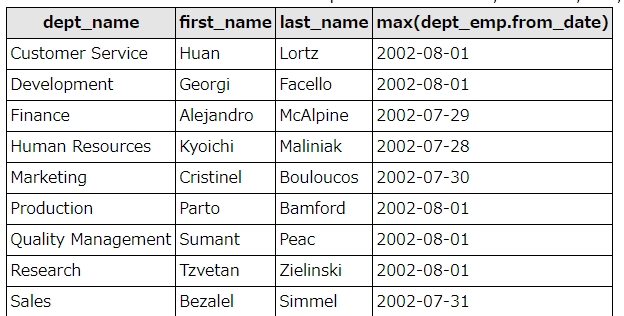
group byで最新のレコードを求める例
dept_emp(社員番号、部署番号の紐付け用テーブル)を使って、各部署の一番の新入社員を求めてみましょう。
日付データに対してminとgroup byを組み合わせることで、グループ内の最新日付のデータを抽出できます。
SELECT departments.dept_name, employees.first_name, employees.last_name, max(dept_emp.from_date) FROM dept_emp left join departments ON departments.dept_no = dept_emp.dept_no left join employees ON dept_emp.emp_no = employees.emp_no WHERE to_date="9999-01-01" GROUP BY departments.dept_name
結果はこうなります。
group byの集計結果をhavingで絞り込む例
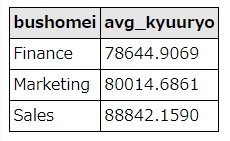
先ほど、group byで部署別の給与平均を出した例を発展させて、「部署別の平均給与(7万ドル超え限定)」を抽出してみます。
SELECT departments.dept_name as bushomei, avg(salary) as avg_kyuuryo FROM salaries left join dept_emp ON dept_emp.emp_no = salaries.emp_no left join departments ON departments.dept_no = dept_emp.dept_no WHERE salaries.to_date="9999-01-01" group by bushomei having avg_kyuuryo > 70000
結果はこうなりました。
結果
group by に続けて、havingに条件を指定すると絞り込みができるんですね。
「whereは、集計前の絞り込み条件」「havingは、集計後の絞り込み条件」を指定する、と覚えておくとよいでしょう。
日付範囲指定でgroup by集計する例

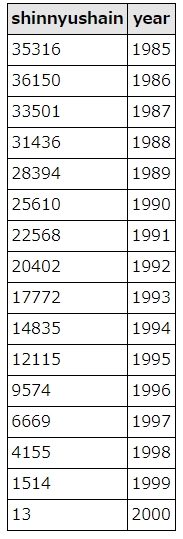
employeesテーブルから、年ごとの新入社員数を求めてみましょう。
SELECT count(*) as shinnyushain, date_format(hire_date,'%Y') as year FROM `employees` group by year
結果はこうなります。
結果
徐々に新入社員の数が減って、なんと2000年には13人。
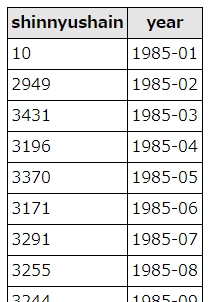
date_format(hire_date,’%Y’) as yearの箇所を、以下のように変更することで、年月別の集計が可能になります。
date_format(hire_date,'%Y-%M') as year
結果


