




SQLのjoinのサンプルコードを集めてみました。
以下、データベースとして、MySQLのサンプルデータベースEmployeesを使っています。SQL実行結果の表示にはphpMyAdminを使用しています。
目次
SQLのjoinの基本

別テーブルの項目を、キーを使って引っ張って来たい、というときに使うのがjoin。
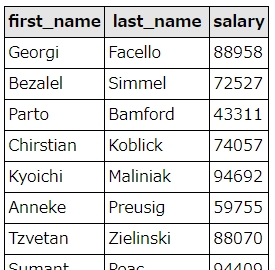
具体的な例だと、employeesテーブルのfist_name(名前)、last_name(姓)と、salary(年収)をemp_no(社員番号)で紐付けて抽出したい…といったときに使います。
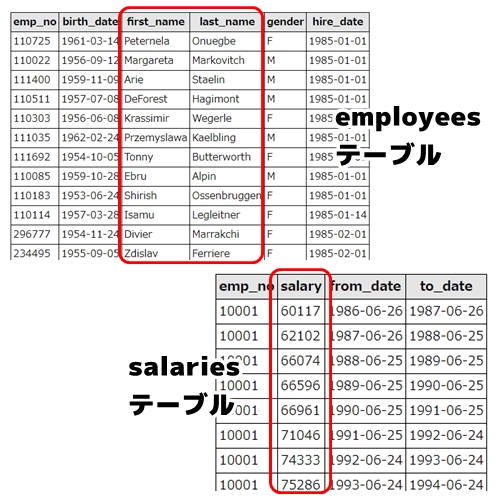
SELECT employees.first_name, employees.last_name, salaries.salary FROM employees left join salaries on employees.emp_no = salaries.emp_no WHERE salaries.to_date = "9999-01-01"
salariesには、各社員の過去の給与情報も含まれているため、最新の給与を抽出するために「salaries.to_date = “9999-01-01″」という条件を追加しています。
結果は、こうなります。
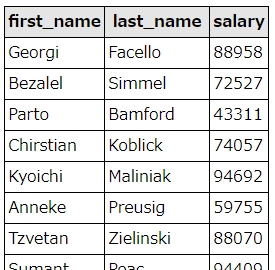
結果
今回の例では、外部結合(アウタージョイン)のLEFT JOINを使用しました。
続いて、内部結合・外部結合の違いと、LEFT JOIN、RIGHT JOIN、INNER JOINの違いを見て行きましょう。
SQLの内部結合と外部結合の違い
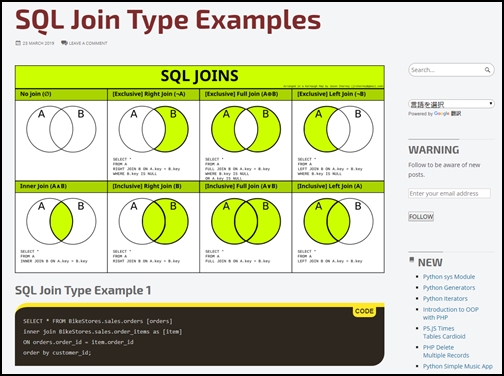
参考)SQL Join Type Examples – TrueCodes
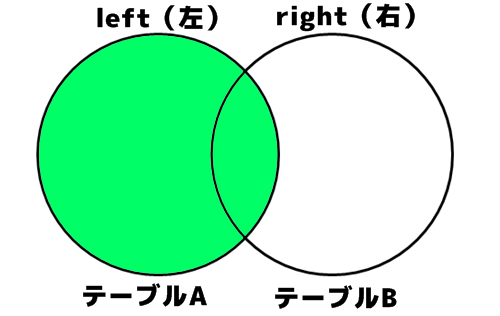
SQLのjoinのパターンは、よくベン図で説明されています。
テーブルAとテーブルBの結合を、ベン図で表すと全部で8パターン。
しかし、実際にSQLで使用するのは内部結合(インナージョイン)と、外部結合(アウタージョイン)のLEFTジョインの2つだけです。
内部結合(インナージョイン)
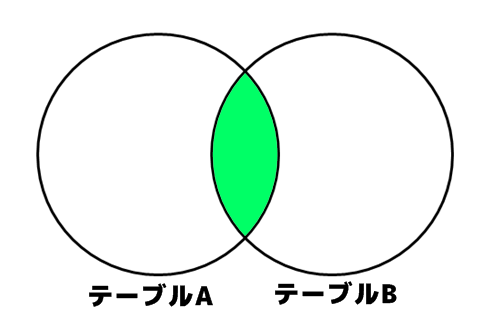
指定したキーの値が、テーブルAとテーブルB両方に存在するレコードのみを抽出します。
SELECT employees.first_name, employees.last_name, salaries.salary FROM employees inner join salaries on employees.emp_no = salaries.emp_no WHERE salaries.to_date = "9999-01-01"
もしもsalariesテーブルに給与情報がない社員が居た場合、データが抽出されません。
外部結合(アウタージョイン)のLEFTジョイン
LEFT ジョインは、上記のSQLの「inner join」が、「left join」に変わります。
インナージョインの指定
inner join salaries on employees.emp_no = salaries.emp_no
LEFTジョインの指定
left join salaries on employees.emp_no = salaries.emp_no
LEFT JOINの「LEFT」とは、このベン図を見た時の左側(LEFT)を主体にデータを取得するという意味だったんですね。
この場合、テーブルAを主体にして、テーブルB上にデータがなくても「NULL」としてデータを結合します。
試しに「employees」テーブルに「YAMADA TARO」という社員データを追加し、salariesテーブルはそのままにします。
employesテーブルにはデータがあるのに、salariesテーブルにはデータがない状態になります。

わかりやすくするため、条件に「first_nameがTAROのレコードのみ」という条件を追加しました。
SELECT employees.first_name, employees.last_name, salaries.salary FROM employees left join salaries on employees.emp_no = salaries.emp_no WHERE employees.first_name = "TARO"
結果はこうなります。

結果
なお、RIGHT JOINは、記述の順番を変えることでLEFT JOINに書き換えることが可能です。
人によっては、SQLの可読性をあげるためにRIGHT JOINは使わずに、全てLEFT JOINで記述するという人もいるくらいです。
SQLのJOINが遅い場合の、簡易的なSQLチューニング方法

「Joinしたテーブルが遅い」という場合、例えばorder byの並び替え項目指定の違いで、速度が大きく変わることがあります。
SELECT
employees.first_name,
employees.last_name,
departments.dept_name
FROM
`employees`
left join dept_emp on employees.emp_no = dept_emp.emp_no
left join departments on dept_emp.dept_no = departments.dept_no
order by employees.emp_no
結果
約33万件のクエリの実行にかかった時間は、0.0005秒。
331603 total, Query took 0.0005 seconds
order byの指定を以下のように変えて実行してみます。
order by dept_emp.emp_no
331603 total, Query took 0.8373 seconds.
全く同じ実行結果ですが、かかる時間は0.8373秒になりました。
比較すると、1674倍の時間がかかっています。

joinしたテーブルに対して、order byの指定の仕方が異なるだけでパフォーマンスが1,000倍以上変わることがある。
なぜ、ここまで速度が変わるんでしょうか?
速度低下の原因は、SQLが内部的にどのような処理をおこなっているかを表示させる「explain」で見ることができます。
explainで見るべき項目
単純にSQLの最初に「explain」を追加することで、SQLの解析結果を確認できます。
EXPLAIN SELECT employees.first_name, employees.last_name, departments.dept_name FROM employees left join dept_emp on employees.emp_no = dept_emp.emp_no left join departments on dept_emp.dept_no = departments.dept_no order by dept_emp.emp_no
実行すると、SQL内で使っている3テーブルに対して、どのようなアクセスが発生するのかを解析した結果が表示されます。
参考)MySQL :: MySQL 5.6 リファレンスマニュアル :: 8.8.2 EXPLAIN 出力フォーマット

見るべき項目は6つで、その中でもtype、key、rows、Extraの4項目に注目。
- employeesテーブルのtype=ALL → テーブルフルスキャンという重い処理が実行されている
- key=NULL → アクセス時にインデックスが使用されていない
- rows=299247, filterd=100.00 → 対象データ件数は、299247件×100.00%で、約30万件
- Extra=Using tempporary、Using filesort → 一時テーブルが使用されている、ファイルソートが使用されている。
並び替え指定を「 order by employees.emp_no 」に変更すると、Explainの内容はこのように変わります。

- employeesテーブルのtype=index → インデックスを使って高速アクセスされている
- key=PRIMARY → 主キー(PRIMARYキー)インデックスを使用している
- Extra=NULL → 一時テーブルもファイルソートもおこなっていない
結果は同じでも、内部的な処理はまったく違っているんですね。
joinを使ったSQLが遅い場合には、特に件数(rows × filterd )の多いテーブルで、type=ALL(テーブルフルスキャン)のような重い処理が実行されていないかどうかをチェックしてみましょう。
- SQLが遅い場合は、explainである程度遅い原因を確認できる
- 件数が多いテーブルで重い処理が実行されているときは要注意
- なるべくインデックスを使って処理されるよう、order byなどの指定を変えてみる



LEFT JOINのLEFTは、ベン図を書いたときの左側のテーブルを主体にする、という意味