




SQLのCASE式の便利な使い方をサンプルつきでまとめました。
なお、MySQLのサンプルデータベースEmployeesを、SQL実行結果の表示にはphpMyAdminを使って解説しています。
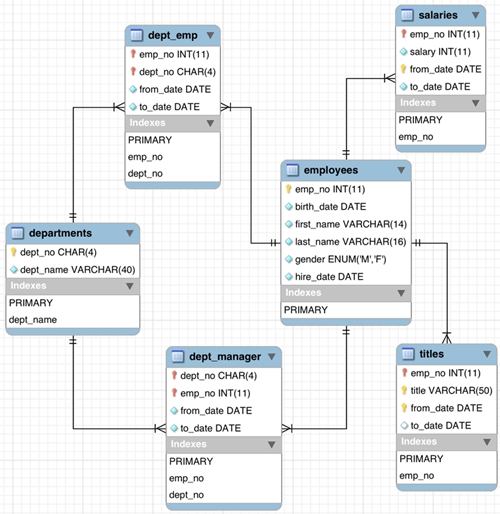
Employeesテーブルの構造は、 Employees Structureを参照してください。
目次
CASE式で、SQL内の分岐や比較ができる

書式は以下の通り。
CASE case_value WHEN when_value THEN statement_list [WHEN when_value THEN statement_list] ... [ELSE statement_list] END CASE
MySQL :: MySQL 5.6 リファレンスマニュアル :: 13.6.5.1 CASE 構文
SQL内だけで、分岐や比較処理ができる便利な構文です。
実際に、使ってみましょう。
employeesデータベースの、departments(部署)テーブルの「Sales」を「営業部」、その他を「それ以外」としてデータをselectしてみます。
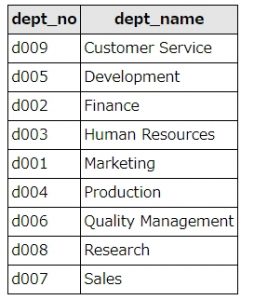
departmentsテーブル
実行するSQLクエリは以下の通り。
SELECT `dept_no`, case `dept_name` when 'Sales' then '営業部' else 'それ以外' end as jpname_dept FROM `departments`
結果は、こうなります。
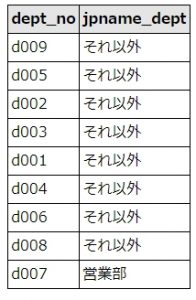
結果
上記の書き方を「単純case式」と言います。
caseで比較するカラムが1つだけなら、これでいいのですが、複数カラムを使った条件の場合はどうすればよいのでしょうか?
CASEの条件を複数指定する例
employeesテーブルと、dept_empテーブルを結合して、社員名と入社年月日、退職年月日を抽出しました。
SELECT employees.first_name, employees.last_name, dept_emp.from_date, dept_emp.to_date FROM dept_emp, employees WHERE dept_emp.emp_no = employees.emp_no
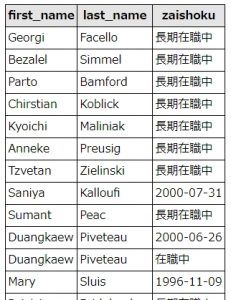
結果は以下の通りです。to_date(退職日)に「9999-01-01」が入っている社員は、在籍中ということを表しています。
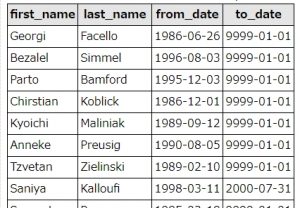
2000年以前入社で在籍中の社員は「長期在籍中」、退職済みの社員は退職年月日、それ以外の社員は「在籍中」としてを抽出するSQLを作ってみましょう。
SELECT employees.first_name, employees.last_name, case when dept_emp.from_date < '2000-01-01' and dept_emp.to_date = '9999-01-01' then '長期在職中' when dept_emp.to_date != '9999-01-01' then dept_emp.to_date else '在職中' end as zaishoku FROM `dept_emp`, employees WHERE dept_emp.emp_no = employees.emp_no
結果はこうなります。
order by にCASEを指定する例
値の大小でもなく、辞書順でもなく、決めた順番でデータを抽出したい場合にCASEを使うと便利です。
SELECT `dept_no`, `dept_name` FROM `departments`
order by
case
when dept_name='Sales' then 1
when dept_name='Development' then 2
when dept_name='Finance' then 3
when dept_name='Production' then 4
when dept_name='Customer Service' then 5
when dept_name='Human Resources' then 6
when dept_name='Quality Management' then 7
when dept_name='Research' then 8
when dept_name='Marketing' then 9
else 99
end
dept_name(部署名)ごとに手動で番号を振り、指定順に並べ替えて表示してみましょう。指定外の部署名が出てきた場合、「else 99」の行により、99が割り振られます。
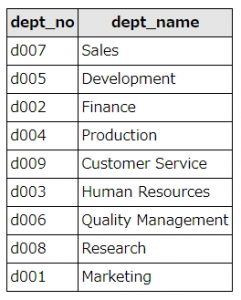
結果
UPDATEでCASEを使って、指定した値を入れ替える
「指定した値を入れ替える」って、意外と難しいですよね。
例えば以下の、employeesテーブルのgender(性別)をM→F、F→Mに入れ替える場合、けっこう悩みませんか?
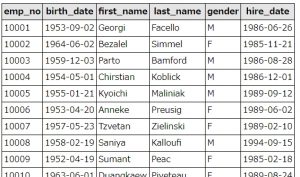
CASEを使うと、比較的かんたんに実現できます。
UPDATE
employees
SET
gender =
case
when gender='M' then 'F'
when gender='F' then 'M'
else gender
end
WHERE
gender in ('M','F')
実行結果は以下のとおり。
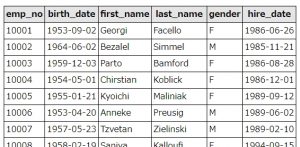
where句の指定は今回あまり意味がないのですが、大量データの入ったテーブルに対して、余計なレコードを更新しないようにするための対策です。
GROUP BYにCASEを使ってcount集計する例
縦に長い(縦持ち)テーブルを、横に長い(横持ち)テーブルに変換して抽出する例です。
employeesデータベースのtitlesテーブルを使って試してみましょう。
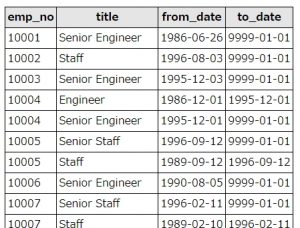
titlesテーブルには、社員番号とタイトル(肩書)、その肩書を持っていた期間が記録されています。人によって、Engineer→Senior Engneerなど肩書が変わった人もいるんですね。
過去に持っていた肩書を横持ちテーブルに変換して抽出してみます。
SELECT
emp_no,
count(case when title='Staff' then 1 else null end) as flg_staff ,
count(case when title='Senior Staff' then 1 else null end) as flg_sstaff ,
count(case when title='Engineer' then 1 else null end) as flg_eng ,
count(case when title='Assistant Engineer' then 1 else null end) as flg_aeng ,
count(case when title='Senior Engineer' then 1 else null end) as flg_seng
FROM
titles
group by emp_no
結果はこうなります。
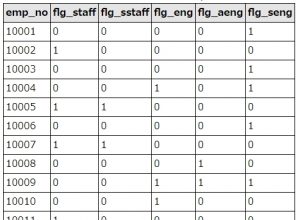
たとえば、emp_no=10004の社員は、EngneerとSenior Engineerの肩書を持った経験がある、ということになります。
処理としては、肩書がある場合は1,ない場合はnullをCASE式で抽出し、countで数を数えています。nullはcountしても0になります。
CASE式のデメリット

アプリ側で処理させなくても、プログラム的な処理をSQLで出来るCASE式。とても便利なのですが、処理速度を低下させる要因の一つでもあります。
たとえば、Microsoft SQLServerの例ですが、case文を使ってNULL判定と表示結果のフォーマットをおこなったところ、12秒の処理が80秒かかってしまったというケースもあるようです。
CASE式使用で、あまりにもパフォーマンスが落ちる場合は、処理をアプリ側に移すなどのチューニングが必要になることも覚えておきましょう。


