




プログラミングにおける基本的なデータ構造に、「キュー」と「スタック」があります。
キューは最初に入れたデータを、最初に取り出す「先入れ先出しの(FIFO)」のデータ構造で、スタックは後から入れたデータを、最初に取り出す「後入れ先出し(LIFO)」データ構造となります。
この記事では、キューとスタックの基本的な概念やデータのイメージから
、Rubyでキューとスタックを使ったデータ処理を行う方法を解説していきます。
目次
キュー(Queue)とは?

先述のとおり、キュー(Queue)は先入れ先出し(FIFO)のデータ構造で、最初に入れたデータから順にデータを取り出していく配列データです。
日常生活の例で例えるなら、人気ラーメン店での店に入れないお客さんが並ぶ待ち行列のように、最初に列に並んだ人から順に、お店の中に入っていくようなイメージです。
コンピューターの世界でもキューは多く使われており、CPUや入出力装置の順番待ちなどに使われています。パソコンの処理が重くて反応が鈍くなるのも、多くのキューが追加されて処理が溜まっていってしまい、後から追加されたキューがなかなか処理されず待たされることが、パソコンが遅くなる要因の一つでもあります。
キューのイメージ
先入れ先出しの(FIFO)のデータ構造では、キューにデータを追加することをエンキュー(enqueue)と呼び、キューの先頭からデータを取り出すことをデキュー(dequeue)と呼びます。
具体的なデータのイメージを見ながらエンキュー(enqueue)とデキュー(dequeue)の動作を、もう少し詳しく確認していきましょう。
まず、エンキュー(enqueue)を行うと、キューを管理する領域(Queueや配列などのオブジェクト)の最後尾にデータが追加されます。
次の例では、データが2、3、4と並んでいるキューに、「データ5」をエンキュー(enqueue)すると、キューの末尾にデータが追加されるのをイメージにしたものです。
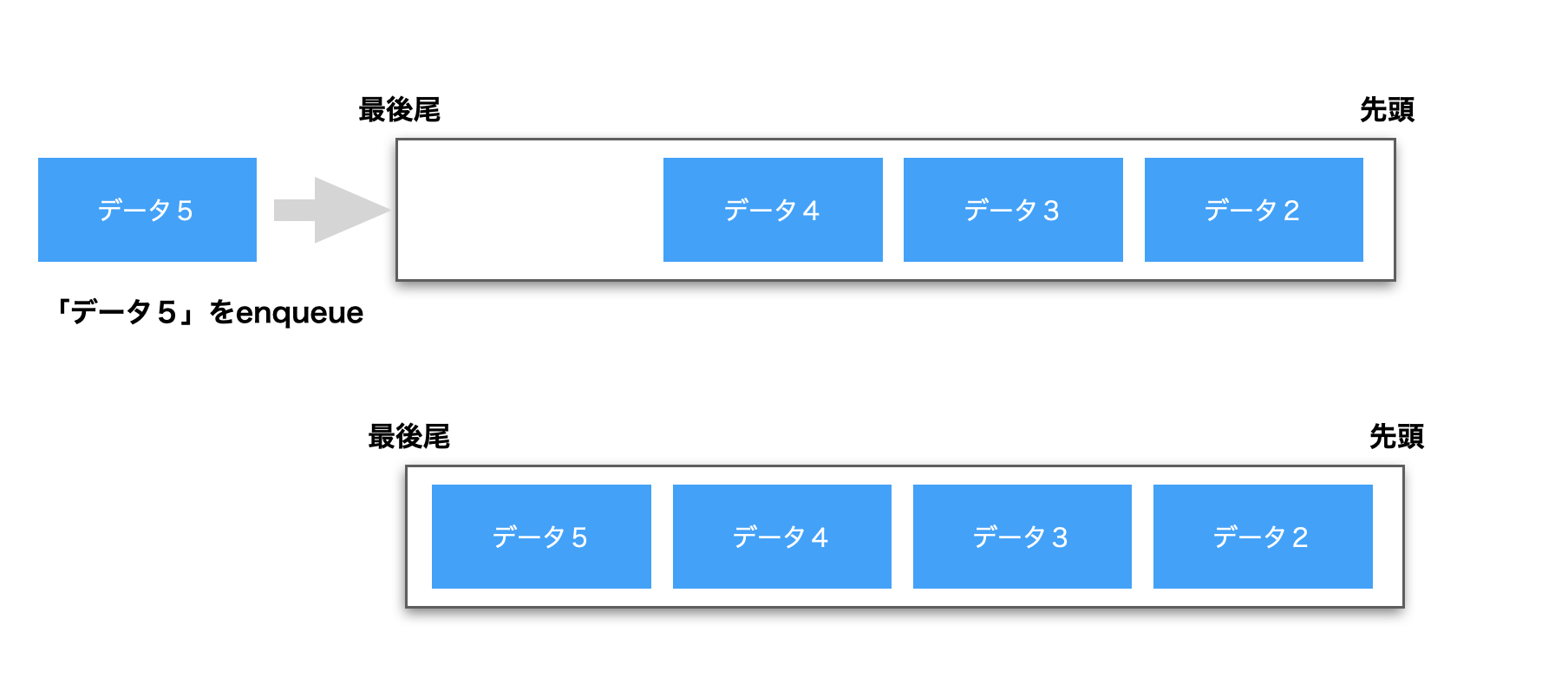
そして、キューからデータを取り出すデキュー(dequeue)をすると、先頭の「データ2」をキューから取り出し、後ろのデータを前に一つずつ詰めていきます。
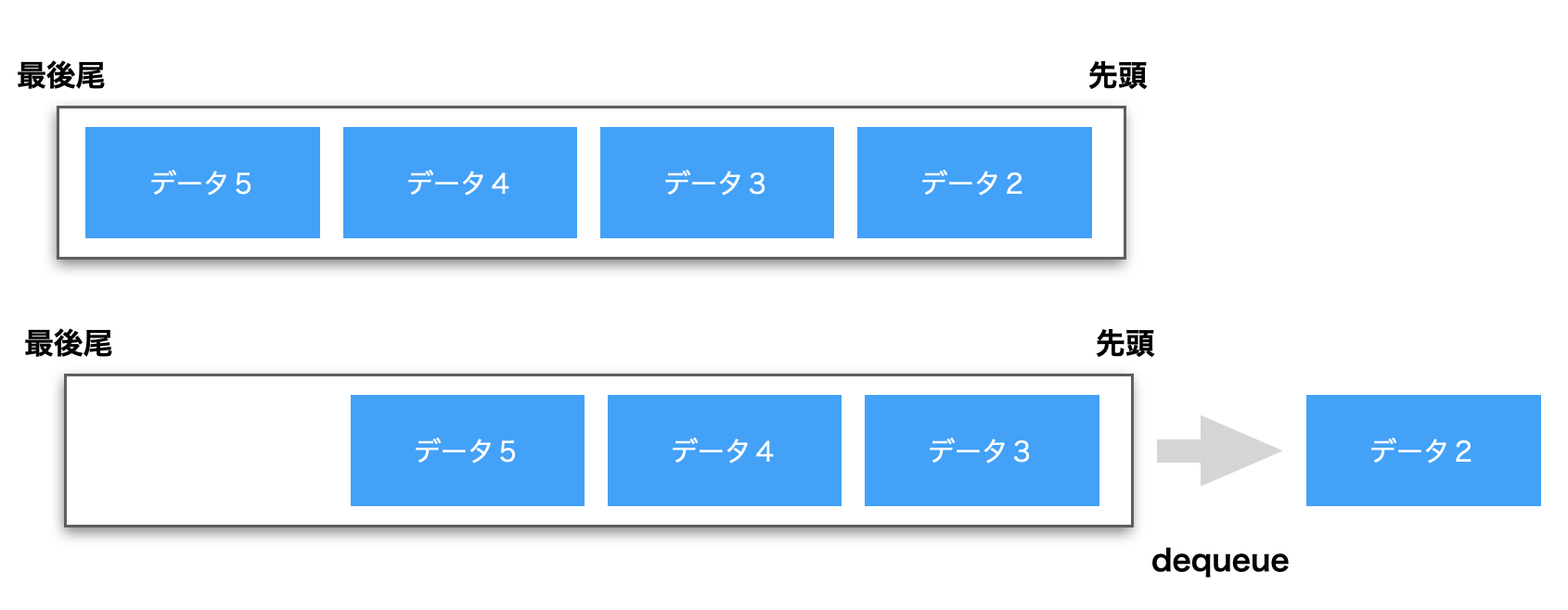
これが、先入れ先出しの(FIFO)データ構造のキューのイメージです。
まさに普段行っている遊園地や、人気飲食店の待ち行列を想像するとイメージしやすいでしょう。
スタックとは?
スタック(Stack)は、後入れ先出し(LIFO)のデータ構造で、最後に入れたデータが最初に取り出される配列データです。
日常生活であれば、下から積み上げた本を上から順に取っていったりすることや、テキストエディタなどて、最後の編集を元に戻す Undo(アンドゥ)」機能なども LIFOに該当します。
普段よく使う、ウェブブラウザの訪問履歴の「戻る」機能なども、積み上がったページの訪問履歴の最後から1つ取り出したページに戻るため、後入れ先出し(LIFO)のデータ構造と言えます。
スタックのイメージ
後入れ先出し(LIFO)のデータ構造では、スタックにデータを積み上げることをプッシュ(push)と呼び、スタックの一番上からデータを取り出すことをポップ(pop)と呼びます。
キューの時と同様に、スタックも具体的なイメージを見ながらプッシュ(push)とポップ(pop)の動作について、もう少し詳しく確認していきましょう。
スタックはコップの中にデータを追加していき、積み上がった一番上からデータを取り出すイメージをすると分かりやすいでしょう。
次の例では、「データ2」「データ3」「データ4」が積まれているスタックに、「データ5」をプッシュ(push)すると、スタックの一番上にデータが追加されるのをイメージにしたものです。
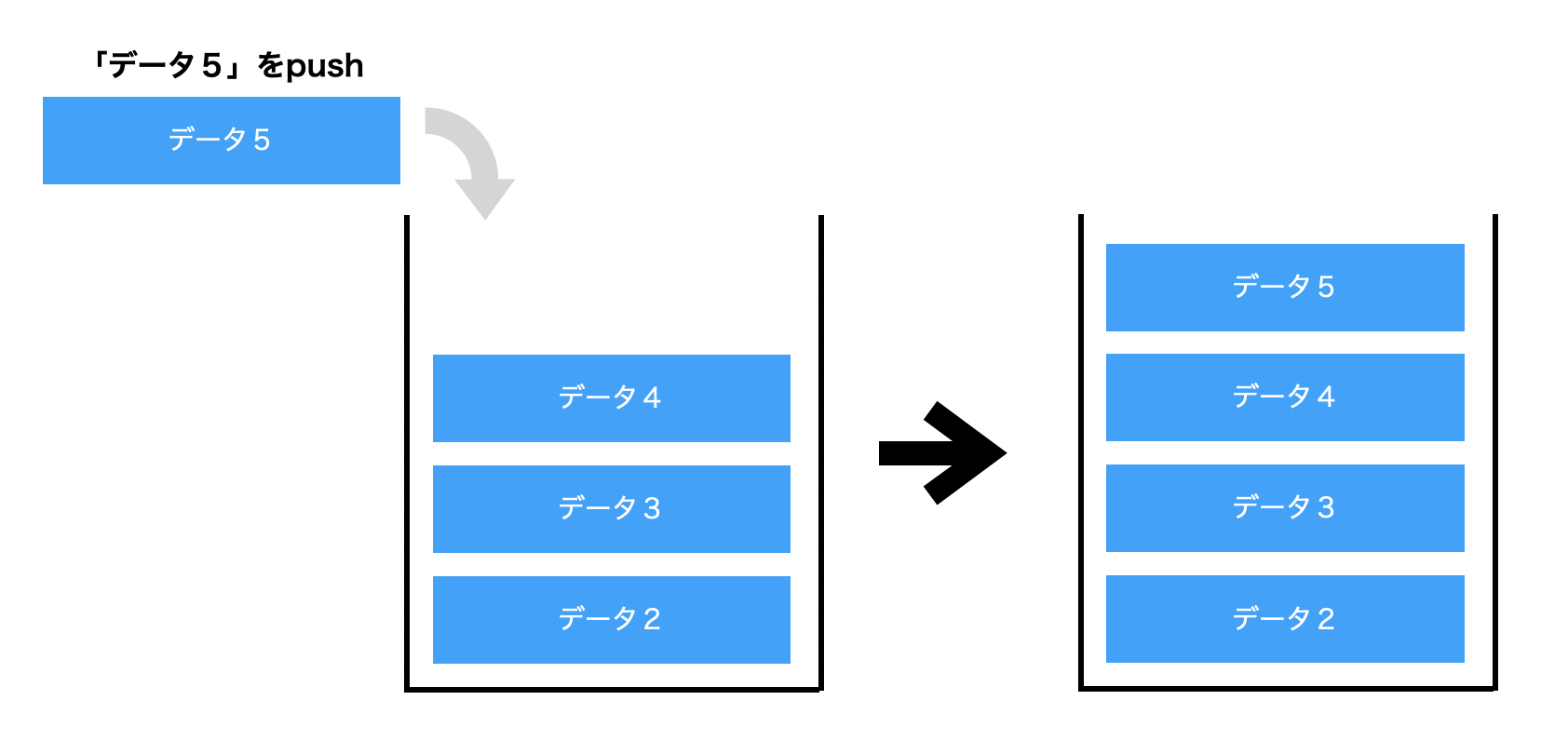
そして、スタックからデータを取り出すポップ(pop)を行うと、スタックの一番上にある「データ2」が取り出されます。
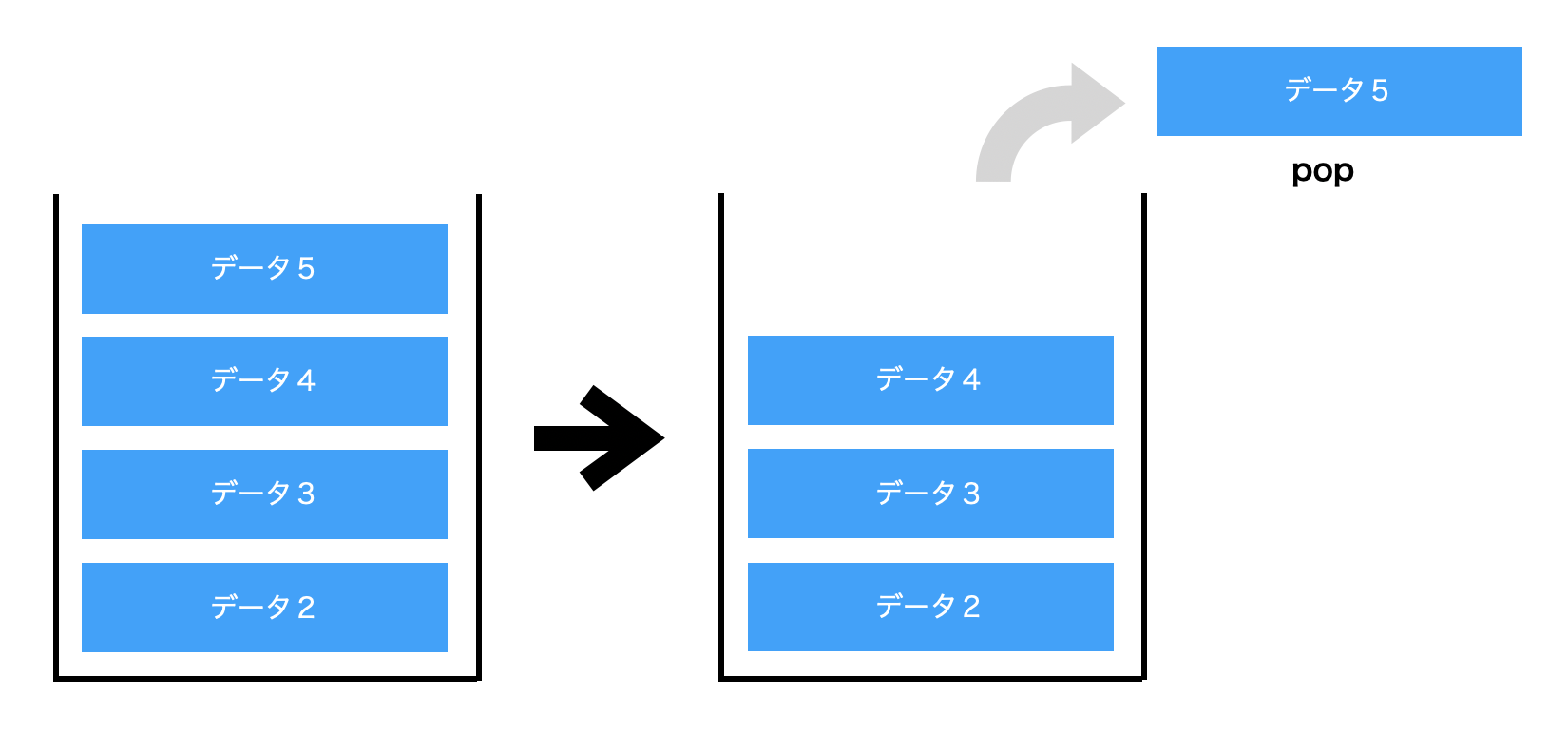
これが、後入れ先出し(LIFO)のデータ構造のイメージです。
キューの実装
キューとスタックの概要を確認したところで、ここからは、Rubyのプログラミングでキューを実装する方法を見ていきましょう。
RubyにはQueueクラスを使ったキューの制御と、配列をキューのように扱う2つの方法でキューの実装が可能です。
Queueクラス
Queueクラスはその名の通り、先入れ先出しの(FIFO)のデータ構造であるキューを管理するクラスです。Thread#enqメソッドでキューにデータを追加し、Thread#deqメソッドでキューの先頭から1件データを取り出します。
require 'thread'
q = Queue.new
th1 = Thread.start do
while resource = q.deq
puts resource
end
end
[:resource1, :resource2, :resource3, nil].each{|r|
q.enq(r)
}
th1.join▪️実行結果
resource1
resource2
resource3配列をキューとして扱う
キューのデータ構造は基本的には配列と同じであるため、配列をキューとして扱う方法もあります。
配列のpushメソッドで、キューにデータを追加(エンキュー)し、デキューはshiftメソッドを使って先頭の要素の取り出しと削除を同時に行います。
queue = []
#データを2件追加(エンキュー)
queue.push 'データ1'
queue.push 'データ2'
queue.push 'データ3'
#データを先頭から取り出す(デキュー)
puts queue.shift
puts queue.shift▪️実行結果
データ1
データ2alias_methodを使用してメソッドに別名をつけると、配列を一層のことキューらしく扱うことができます。次のサンプルコードでは、Arrayクラスのpushメソッドにenqueueを、shiftメソッドにdequeueという別名を付け、以降の処理では別名のメソッドで処理を行います。
class Array
alias_method :enqueue, :push
alias_method :dequeue, :shift
end
queue = []
#データを2件追加(エンキュー)
queue.enqueue 'データ1'
queue.enqueue 'データ2'
queue.enqueue 'データ3'
#データを先頭から取り出す(デキュー)
puts queue.dequeue
puts queue.dequeueスタックの実装

続いて、後入れ先出し(LIFO)のデータ構造を扱うスタックをRubyで実装する方法を見ていきましょう。
スタックの場合は、Queueクラスのような専用のクラスは存在しないため、基本的には配列を使ってスタックのデータ構造を実装します。
配列をスタックとして扱う
配列をスタックとして使う場合、pushメソッドでスタックにデータを追加し、popメソッドでは配列の末尾の要素の取り出しと削除を同時に行います。
stack = []
#データを2件追加(プッシュ)
stack.push 'データ1'
stack.push 'データ2'
stack.push 'データ3'
#データを先頭から取り出す(ポップ)
puts stack.pop
puts stack.pop▪️実行結果
データ3
データ2このように、pushで配列の末尾にデータを追加していき、popメソッドで後から追加したデータから順に配列から取り出されているのが分かります。
まとめ

キューとスタックの基本的な概念と、Rubyのプログラミングでそれらを実装する方法を紹介してきました。キューとスタックは、複数の箇所から要求された依頼を、順番を保証しながら処理を行うために使用するデータ構造で、さまざまなデータを取り扱う昨今のシステム開発ではよく使われています。是非キューとスタックの使い方を覚えておきましょう。
【関連記事】
▶【Ruby入門】配列と操作(基本編)



Thread#deqメソッドは、キューが空(データが0件)の時にメソッドを呼び出すと、呼出元のスレッドは停止します。キューにデータ追加(エンキュー)されるとスレッドが再開します。