




group byによる集約関数の絞りこみ目的で使われるhaving句のサンプルコードを紹介します。
以下、データベースとして、MySQLのサンプルデータベースEmployeesを使っています。SQL実行結果の表示にはphpMyAdminを使用しています。
目次
havingの基本的な使い方

SELECT dept_name, count(emp_no) FROM `dept_emp` left join departments on dept_emp.dept_no = departments.dept_no group by dept_emp.dept_no having count(emp_no) > 30000
上記SQLは、dept_name(部署名)ごとの社員数を取得します。dept_emp(部署・社員紐付けテーブル)とdepartments(部署テーブル)を結合し、dept_no(部署番号)でグルーピングしています。
havingにて、社員数30000以上の部署のみに絞込を行っています。
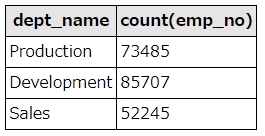
SQL実行結果
havingのサンプルコード

平均値(avg)をhavingで絞り込む
SELECT departments.dept_name as bushomei, avg(salary) as avg_kyuuryo FROM salaries left join dept_emp ON dept_emp.emp_no = salaries.emp_no left join departments ON departments.dept_no = dept_emp.dept_no WHERE salaries.to_date="9999-01-01" group by bushomei having avg_kyuuryo > 70000
上記のSQLは、部署ごとの平均年収を取得しています。salaries(年収テーブル)とdept_emp(部署・社員紐付テーブル)、departments(部署テーブル)をjoinしています。
年収が有効(salaries.to_date=9999-01-01)なもののみ対象に、dept_name(部署名)でグルーピングしています。
havingで、avg(salary)=平均年収70000以上のデータに絞り込みをおこなっています。
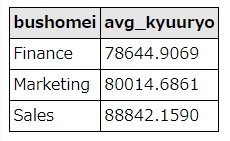
SQL実行結果
【関連記事】
▶SQLのgroup byサンプルコード集 count、like、join等の組み合わせ例
重複レコードを取得するにはcount(*)を条件に組み込む
select emp_no, max(to_date) as to_date, count(*) from salaries group by emp_no having count(*) > 1
上記SQLは、salaries(年収テーブル)の最新日付の重複数を取得しています。havingで、重複が1件以上のデータに絞り込みをおこなっています。
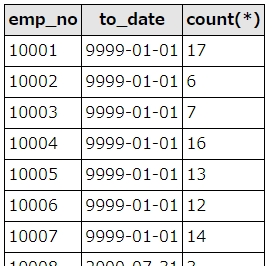
SQL実行結果
havingにサブクエリを使うサンプル
havingの条件にサブクエリを使うことも可能です。
SELECT dept_name,
count(dept_name)
FROM (SELECT dept_name,
title
FROM titles
LEFT JOIN employees
ON titles.emp_no = employees.emp_no
LEFT JOIN dept_emp
ON employees.emp_no = dept_emp.emp_no
LEFT JOIN departments
ON dept_emp.dept_no = departments.dept_no
GROUP BY dept_emp.dept_no,
title) tbl
GROUP BY dept_name
HAVING count(*) = (SELECT count(DISTINCT title)
FROM titles)
上記SQLは、titles(肩書テーブル)に存在する全ての肩書の社員が揃っている部署を取得します。
サブクエリでは、titles(肩書テーブル)、dept_emp(部署・社員紐付けテーブル)、departments(部署)テーブルをleft joinで結合し、dept_no(部署番号)でグルーピングしてdept_name(部署名)、title(肩書)を取得しています。
メインクエリでは、サブクエリの結果をdept_name(部署名)でグルーピングし、dept_name(部署名)と所属する社員の肩書の種類数を取得。havingにて、titlesテーブルに存在する全肩書種類数(=7種類)の社員が揃っている部署のみ取得するよう絞り込みを行ってます。
SQLを実行すると、こうなります。
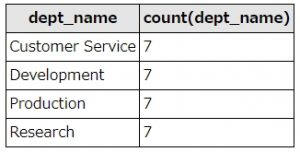
SQL実行結果
whereとhavingの決定的な違いはレスポンス速度
whereとhavingは同じように使えて、結果も同じです。
例えば、以下の2つのクエリは、全く同じ結果になります。
SELECT * FROM `titles` having emp_no > 20000 SELECT * FROM `titles` where emp_no > 20000
※titles(肩書テーブル)から、emp_no(社員番号)20000以上のデータを取得するSQLです。
しかし、explainで実行計画を確認してみると…
where使用のSQLは、インデックスを使用して実行(key=PRIMARY)しています。

一方having使用のSQLは、インデックス不使用(key=NULL)のテーブルフルスキャン(type=ALL)となっています。

件数の少ない単純なクエリでは、さほどレスポンスに差は出ないかも知れません。しかし、基本的にはhavingは遅いものと考えておいて良いでしょう。
having使用は、sumやcount、avgなどの集約関数の絞込時のみにしておきましょう。
主要DBMSのHaving使用時の注意点

Oracle Having 特に注意点なし
LOB列、ネストした表またはVARRAYを条件に指定できない以外は、特に独自の注意点はありませんでした。
MySQL Having 拡張使用でhavingにエイリアス使用可能
標準SQLでは、having句でエイリアスを使うことはできないことになっています。MySQLでは独自の拡張により、having句でのエイリアスが使用可能になってます。
関連)MySQL :: MySQL 5.6 リファレンスマニュアル :: 12.19.3 MySQL での GROUP BY の処理
SQL Server Having 特に注意点なし
havingではtext、image、ntext型は使用できない点以外は特に独自の注意点はありませんでした。
関連)HAVING (Transact-SQL) – SQL Server | Microsoft Docs
PostgreSQL Having 特に注意点なし
FOR NO KEY UPDATE、FOR UPDATE、FOR SHARE、FOR KEY SHAREを併用して使うことができない点以外は、特にhavingに関する独自の注意点はありませんでした。
まとめ


- havingはsumやavg、countなどの集約関数に絞り込みをおこなう
- countとの組み合わせで、重複しているレコードの数を取得可能
- havngにはサブクエリも使用可能
- whereとhavingは同じように使えるが、havingはインデックスを使わないため遅くなる可能性が高い
- 主要DBMSでは、havingの仕様に大きな違いはない


