




SQLのlimit句の使い方についてまとめました。
limit句は大量レコードのページングや、最新・最古の一件を取得するようなケースでよく使われます。
目次
limit句の使い方

以下のサンプルコードは、MySQL前提となります。データベースとして、MySQLのサンプルデータベースEmployeesを使っています。
limit句の構文
select * from `salaries` where emp_no > 20000 order by to_date desc limit 0, 10
取得データの上限設定の指定のために使います。
カンマ指定時は、limit <開始位置>,<最大取得件数>と指定可能です。「limit 取得したい行数 OFFSET 開始位置」と意味は同じです。
件数が多いテーブルに対してlimitを設定してselectすると、レスポンス時間を短くできます。ページングをおこなうときに便利です。
limitは、標準SQLではないため、主要DBMSでは使えないものもあります。MySQLとPostgreSQLでは使用可能ですが、OracleやSQL ServerではLimit句が使えません。
そのため、Oracleでは、ROWNUMを使って擬似的にlimitと似た動作を実現可能です。
SQL Serverの場合は、OFFSET x ROWSやFETCH NEXT x ROWS ONLYといった命令を組み合わせて、limitと同様の動作を実現しています。
limitを使って、抽出結果の最新データを取得

select * from salaries order by emp_no desc limit 1
order by 、descと limit 1の組み合わせで、最新の一件を取得できます。
最新の十件を昇順にソートしたいような場合は、サブクエリ(副問い合わせ)を組み合わせます。
select * from (select * from salaries order by emp_no desc limit 10) as A order by emp_no
emp_no(10001~499999)の大きいものから10件取得し、昇順(数字の小さい順)にソートできました。
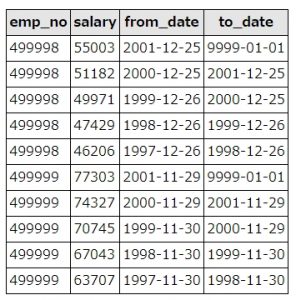
SQL実行結果
limitを使ってランダムに指定件数のデータを抽出する
乱数をorder byに指定すると、テーブル全体から指定件数をランダムに抽出することが可能です。
たとえば、salariesテーブルからランダムに10件抽出するには、以下のSQLを実行すれば可能。
select * from salaries order by Rand() limit 10
実行すると、1.2秒かかりました。
- 10 total, Query took 1.2157 seconds.
ただし、レコード全件にレコードを割り振るため、かなり遅くなります。
サブクエリでlimit使用時のエラー

MySQLでは、サブクエリ内でlimitを使うとエラーになります。
select *
from employees
where emp_no in (select emp_no
from titles
limit 10)
上記のSQLを実行すると、下記のエラーが出力されます。
ERROR 1235 (42000): This version of MySQL doesn't yet support 'LIMIT & IN/ALL/ANY/SOME subquery'
「MySQLのこのバージョンでは、IN、ALL、ANY、SOMEサブクエリとLIMITを同時に使えない」というエラー内容です。
select * from employees where emp_no in (select emp_no from (select emp_no from titles limit 10) as employees2)
上記のSQLのように「サブクエリのサブクエリ」と言う形にし、in句内に直接limitが出現しないように工夫することでエラー回避が可能です。
limit使用で速度が低下するケース

ページングのためにlimitとoffsetを組み合わせると、offsetの値が大きくなるにつれ速度は遅くなります。
例えば、「limit 100,10」という指定では、内部で110件取得して先頭から100個捨てる処理をおこなうためです。クエリを実行するたびに、毎回OFFSET分の検索をおこなっているんですね。
実際、どのくらい処理時間が変わるのか、比較してみましょう。
283万件のデータが保存されているsalariesテーブルで、以下のSQLを実行してみます。
select * from `salaries` limit 0,100
- 100 total, Query took 0.0003 seconds.
offsetが0の状態で、0.003秒です。
select * from `salaries` limit 2000000,100
- 100 total, Query took 0.3642 seconds.
offsetに2,000,000を設定すると、処理時間が1214倍になりました。
1ページあたり100レコード表示するとして、1万ページ目にはレスポンス時間が1,214倍になります。
limitのパフォーマンスを改善するには、where句でページ条件を指定
select * from employees WHERE emp_no >20000 LIMIT 10
offsetの代わりに、where句の条件を変化させることでページング時の速度低下を改善できる可能性があります。
ただし、抽出条件に沿った連番・抜け無しのIDカラムがあることが前提になるため、使える局面は限定的と言えるでしょう。
offset以外の要因で、ページングのパフォーマンスが低下する原因はインデックスだというケースがあります。
以下のSQLを実行したときの実行時間を計測してみました。
select * from `salaries` where emp_no>20000 order by to_date limit 1
- 1 total, Query took 0.7003 seconds.
以下のSQLを実行し、salariesテーブルにto_date、emp_noの2カラムのインデックスを設定します。
alter table salaries add index (to_date, emp_no)
上記のselect文を実行すると、以下の実行時間となりました。
- 1 total, Query took 0.0003 seconds.

インデックスを設定すると、実行時間が1/2334に短縮できました。
limitのまとめ

- limitはページング用に使うのが便利
- offsetの値が大きくなると、実行速度が遅くなる
- offsetの代わりにwhere句でページング条件を指定すると速度改善の可能性あり
- where句とlimit句の組み合わせはインデックス設定で速度改善の可能性あり



単純計算で、100ページまでページングをおこなうと、レスポンス時間が6倍程度になります。