




データベースを操作するSQLではDISTINCTを使うことで、簡単に重複するデータを取り除けます。ではRubyではどうでしょうか。Rubyでも配列を対象にuniqメソッドを使うことで、重複する要素を取り除くことが可能です。
今回はRubyでuniqメソッドを使った重複データを除外する方法とそれ使用例を紹介します。
目次
重複したデータを除外する方法とは

データベースを処理するためのクエリーには昔から重複したデータを除外する処理が使われていました。なおクエリーとは多くのデータを蓄積したデータベースから目的のリストを抽出するための処理のことで、SQLで記述します。
よく使われるSQLが特定の項目毎に集計したリストの作成です。そして抽出した項目は通常、重複したデータを除外された後に項目毎に集計されます。なおデータベースではDISTINCTを利用したSQLを使うことで重複したデータを除外したリストを作成できます。
表計算で重複したデータを除外する
表計算ソフトはオフィスで最もよく使われるアプリケーションで、ビジネスで扱うリストの多くがExcelなどの表計算ソフトで処理されています。
Excelで重複したデータを除外するには、標準で組み込まれているピボットを使います。このピボットは、先ほど紹介したSQLのDISTINCTと同じように特定の項目毎に集計したリストを作成する機能です。
Excelのピボットを使うと重複を除外した項目に該当する集計値をGUI環境で重複したデータを除外したリストを作成できます。
プログラムで重複したデータを除外するには
昔から特定の項目毎に集計したリストの作成が行われていますが、毎回同じ処理をやるのならプログラムを組んで処理したほうが簡単です。
そのためにはリストの中の特定の項目をすべてチェックし、そこからユニークなもののみを抽出したリストを作らなければなりません。
そのようなプログラムを作るのは、配列とループを組み合わせれば難しくありません。しかしRubyにはuniqメソッドがあり、これを使えば簡単に重複したデータを除外したリストを作れます。
Rubyのuniqメソッドとは
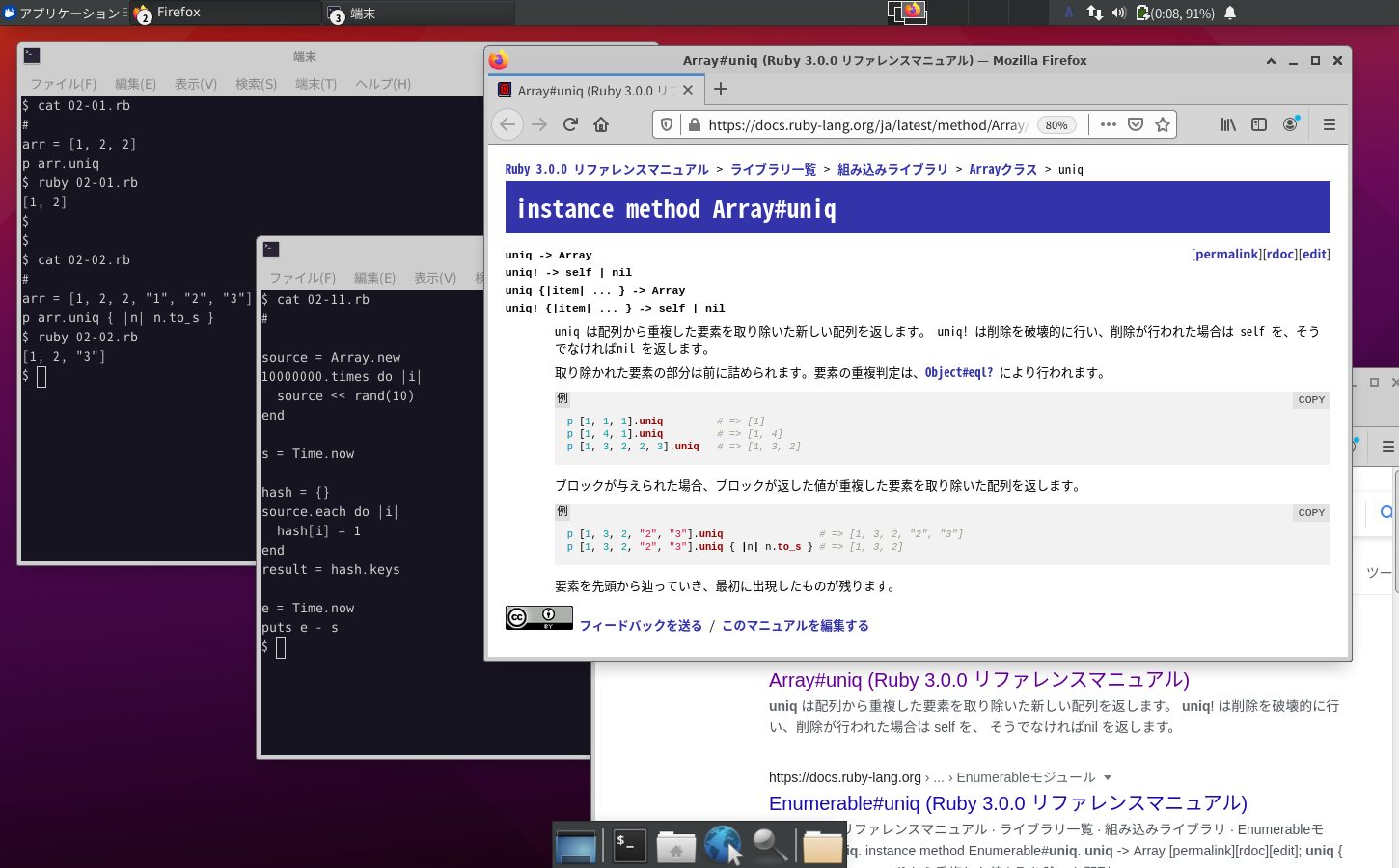
Rubyには配列を操作するメソッドがたくさんありますが、今回紹介するuniqメソッドもそのような配列のメソッドの1つです。そしてuniqメソッドは配列の要素を評価し、そのうえで重複した値を削除したリストを作成します。
なお配列と同じようなハッシュにはuniqメソッドが無いので注意してください。次からuniqメソッドの基本について解説します。
uniqメソッドの文法
uniqメソッドは配列クラスのメソッドで配列を対象とし、配列から重複した要素を取り除いた新しい配列を返します。なお、重複する要素が1つも無い場合は、対象の配列そのものを返します。
uniqメソッドの文法
重複を除外した配列 = 配列.uniq
なお、uniqメソッドによって作られる配列は、重複した要素が削除され、その次の要素が1つ前に詰められます。
uniqメソッドの使用例
arr = [1, 2, 2 ] p arr.uniq # [1, 2] が表示される
uniqメソッドにブロックを指定した場合
Rubyにはブロックを使えるメソッドがいくつもありますが、今回紹介しているuniqメソッドもブロックを指定可能です。そしてuniqメソッドにブロックを指定すると、ブロックで指定された条件に該当した要素を対象に、重複した要素を取り除いた配列を返します。
uniqメソッドの文法(ブロックあり)
重複を除外した配列 = 配列.uniq { |要素の評価に使う変数| 条件 }
ブロックありuniqメソッドの使用例
arr = [1, 2, 2, "1", "2", "3"]
p arr.uniq { |n| n.to_s } # [1, 2, "3"]が表示される
ブロック中の「n.to_s」で配列の要素を文字列に変換してから評価します。そのためこの例では数字の1と文字列の”1″が重複していると判断されるので、先にある数字1と2と文字列の”3″のリストが作られます。
uniq!メソッドは元の配列を書き換える
配列メソッドにはuniqメソッドとは別にuniq!メソッドがあります。uniq!メソッドは配列から重複した要素を取り除くのは同じですが、元の配列を書き換えてしまう点が違います。
またuniq!は、要素を削除した場合は削除後の元の配列を、また削除がなかった場合はnilを返します。なお要素を削除した場合、要素が前に詰められる点はuniqメソッドと同じです。さらにuniqメソッドと同じくブロックも使用できます。
uniq!メソッドの文法
配列.uniq!
配列.uniq! { |要素の評価に使う変数| 条件 }
uniqを使わずに重複したデータを除外する方法

uniqはシンプルに配列から重複したデータを除外できるメソッドですが、データによっては処理速度が遅い、というのが欠点です。もしuniqメソッドを使わずに別の方法で重複したデータを除外したい、という方にハッシュを使った方法を紹介します。
ハッシュを用いた重複したデータを除外する方法
Rubyにおけるハッシュとは、配列のように複数の要素をまとめて管理するオブジェクトで、配列におけるインデックスの数字の代わりにキーを用います。このキーを利用することで重複したデータの削除が可能です。
まずは配列のすべての要素をハッシュのキーとして用いたハッシュを作ってください。この際、重複した値があると、既に作成したキーのハッシュを上書きします。そのため配列のすべての要素をハッシュに変換すると、ユニークなキーのハッシュが作られます。後はそのハッシュを配列に変換すれば重複したデータを除外した配列ができます。
ハッシュを用いた重複したデータを除外する例
次にハッシュを用いた重複したデータを除外する例を紹介します。
hash = {}
source.each do |key|
hash[key] = 1
end
result = hash.keys
この例は重複したデータを除外したい配列sourceの全ての要素をキーとして、hashというハッシュを作ります。なお、hashの値はなんでもかまいません。そして、hash.keysでハッシュのキーを配列に戻すことで重複したデータを除外した配列が作れます。
上記の例をuniqメソッドで書くと次のとおりです。
result = source.uniq
ハッシュを用いた方法のメリット
uniqメソッドは標準の組み込みメソッドのため、プログラムを組みよりも高速で動作します。対象となる要素の数が少ないケースでは、uniqメソッドを利用してください。
ただしRubyの処理速度は速いとはいえません。またuniqメソッドではすべての要素をチェックして重複した要素を除外します。数が多いとRubyの処理が遅さが目立ちます。
その点ハッシュを使った方法はハッシュのキーを呼び出すだけなので、データによってはuniqよりも早く処理できます。もしuniqメソッドの処理が遅いと感じたら、ハッシュを使った方法も検討してください。
まとめ

これまで紹介したようにRubyで重複したデータを除外する際、配列に対してuniqメソッドを使うことで簡単に除外済の配列が作れます。またブロックに条件式を追加して、特定の条件に該当するユニークな要素のみを抽出することも可能です。Rubyで集計データを作成するプログラムなどで利用してください。
なおRubyでは、uniqメソッドを使わずにハッシュを使って重複したデータを除外する処理も作れます。データによってはハッシュを使った方が高速に処理できることもあるので、もしuniqメソッドの処理が遅いと感じたら、ハッシュを用いた方法も検討してください。


