




前記事「正規表現とは何か」では、正規表現の基本を解説しました。
解説を読まれた方々の中には、正規表現の解説としてある種の物足りなさを感じた方もおられるでしょう。
というのも、先の記事の冒頭の例は「ハイフンを除去する」なのに、最後まで検索しか触れていませんでした。
そうです、正規表現における検索以外のもう1つの仕事「置換」について触れていないのです。
よって、本記事では検索ともう一つ、正規表現の重要な役割である置換について解説します。
前回と同様、いきなりRubyのコードで解説せず、エディター(Sublime Text)を使って解説します。
目次
正規表現を使った置換とは
基本的には検索のときに使ったテクニックを応用します。
マッチしたい文字列と、置き換えたい文字列を指定します。
単純な例でみてみましょう。
123-1234 123-4567 345-6789
これを、以下のように指定します。
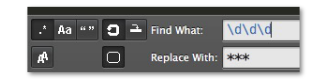
結果はこうなります。
***-***4 ***-***7 ***-***9
数字3文字がアスタリスク3文字に置換できました。
数字3文字というパターンを指定して置換しました。普通の文字列置換とはちがう雰囲気を、感じていただけたでしょうか?
代表的な正規表現の置換例
先の例は正直言って役に立ちませんが、以降は実際に使えそうな置換を解説します。
空行を削除する
空行を削除する、別の言い方をすれば「行頭が改行コード」となります。これを消せばOKです。
123-1234 123-4567 345-6789 あああああ
置換条件に以下を入れてください。
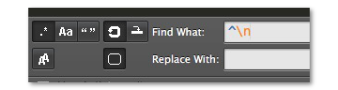
この置換を実行した結果が以下です。
123-1234 123-4567 345-6789 あああああ
行頭がいきなり改行、つまり空白行を削除できました。
行末の空白を削除する
行末を表すメタ文字$を使います。見た目には分かりませんが、行末に空白があります。
123-1234 123-4567 345-6789 あああああ
置換条件に以下を入れてください。
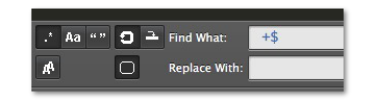
空白1つとプラス、ドルマークです。プラスは1回以上の繰り返しを表すメタ文字です。
この置換を実行した結果が以下です。
123-1234 123-4567 345-6789 あああああ
しつこいようですが、行末に空白があったのですが消えています。
行を削除する
ある特定の条件を満たす行を消すことができます。
例えば、英数字以外で開始する行を消してみましょう。
123-1234 123-4567 345-6789 あああああ
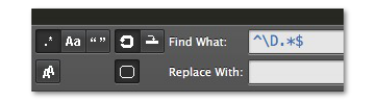
この置換を実行した結果が以下です。
123-1234 123-4567 345-6789
英数字以外で開始している一番下の行が消えました。
ハイフンを消す
さらに複雑な置換にチャレンジしてみましょう。
前回の記事の、郵便番号のハイフンを消す置換です。
123-1234 123-4567 345-6789
上記からハイフンを消してみましょう。

この置換を実行した結果が以下です。
1231234 1234567 3456789
一体何が起こったのでしょうか?じっくり解説します。
変換結果を変数に入れる
もう一度正規表現を見てみましょう。
^(\d{3})-(\d{4}).*$
カッコで囲った箇所が2つあります。正規表現の置換において、カッコで囲うと合致する部分を変数に格納することができます。
カッコで囲ったあとは、$プラス順番でそれを呼び出せます。つまり、最初の(\d{3})を$1、2つ目の(\d{4})を$2として使えるわけです。
1つめのカッコと2つ目のカッコの間のハイフンを取って(つまりつなげて)$1$2と表現することにより、直接結果を結合してハイフンを消すことができました。
URLからドメインを抽出
URLからドメインを抽出、つまりドメインを残してその他は消してしまいましょう。
https://style.potepan.com/aaaaa https://www.potepan.com/ http://www.potepan.com/ https://potepan.com/ https://aaaaaaaa.potepan.com/ https://potepan.com/

この置換を実行した結果が以下です。
style.potepan.com potepan.com potepan.com potepan.com aaaaaaaa.potepan.com potepan.com
解説します。
先頭はhttpまたはhttpsで始まるので、いずれかに一致するものという意味の( | )を使います。
(http|https)とすることで、httpまたはhttpsのいずれかという選択ができます。
続けて「[^/]+」ときます。これは「/」の直前の文字が1文字以上、つまりhttpまたはhttps://から次の/までという意味になります。
先ほど述べた通り、$3とすることで3つめのカッコのみという指定ができます。
よって、前述の結果が得られたというわけです。
h2タグの中身だけを取り出す
h2タグで囲まれた中身だけを抽出しましょう。
<h2>aaaaaa</h2> <h2>bbbbbb</h2> <h2>cccccc</h2>
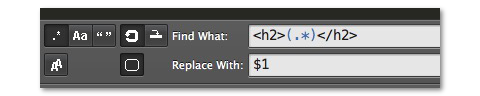
この置換を実行した結果が以下です。
aaaaaa bbbbbb cccccc
h2タグの開始と終了を指定します。その中身が問題です。
カッコの中の.*は、任意の一文字が0回以上繰り返すという意味です。
それをカッコで囲ったので、置換結果で$1とすることで中身を取り出すことができました。
キャプチャ
最後にキャプチャという便利な機能を解説します。
とあるチェックでマッチしたものを以降で使える、というものです。
以下のような文章があったとしましょう。
今日は雨だった。明日も雨かなあ。 今日は晴れだった。明日も晴れかなあ。 今日は曇りだった。明日も曇りかなあ。
この文章は、「今日は<天気>だった。明日も<天気、つまり前とおなじ>かなあ。」というように、前の文章と同じ天気が後ろの文章に続く、というものです。
これを天気だけ抽出するには、以下のようにしてください。

この置換を実行した結果が以下です。
雨 晴れ 曇り
解説しますと、1つめの( )でマッチしたものが、後ろで\1として呼ばれています。
前の文章で(.+)とは何がマッチするか決まっていません。しかし後ろの文章でヒットしたものを使いたい、という場合にキャプチャはとても便利です。
まとめ
本記事では、正規表現を用いた置換を解説しました。
正規表現の置換は、まだまだたくさんの手法があります。本記事の内容に物足りなさを感じたら、是非ともご自身でいろいろと試してみてくださいね!


